
作者:lewisywliu,腾讯PCG客户端开发工程师
ChatGPT是什么
首先从全称看,Chat Generative Pre-trained Transformer,分为两部分。前部分为chat,聊天,ChatGPT是从聊天切入人们的生活,从聊天开始,但是又不止于聊天。后半部分是使用到的相关模型与架构。
G是生成式,P是预训练模型,T是Transformer架构。
其中的生成式,与之对应的还有判别式,像人脸识别之类的都属于判别式。生成式,表示了模型是生成、预测数据的,而ChatGPT是,根据前文单词来预测生成当前的单词,最终生成整个回答。

这里也问了一下ChatGPT,从回复中可以看出,ChatGPT就是一个聊天机器人,但是他比其他的机器人更加的智能,知道的东西更多。
ChatGPT发展历程
ChatGPT一开始是基于GPT3.5的,现在最新的是基于GPT4。那GPT是怎么发展过来的呢,那就要从很久以前说起。
前世
2003年Bengio提出NNLM
时间上应该更早点(2003年是论文发表时间)。即神经网络语言模型,这里将神经网络和自然语言模型相结合,可以说是一个开创性的思想,之后很多年的时间,自然语言模型都是围绕着神经网络来开展的。
除了神经网络,论文中还引入了词嵌入的概念,将离散的单词字符转换成连续空间的向量。不过NNLM的输入是固定长度的词嵌入,所以导致了无法处理长距离的预览关系(即无法处理长上下文信息)。
2010年谷歌提出RNNLM
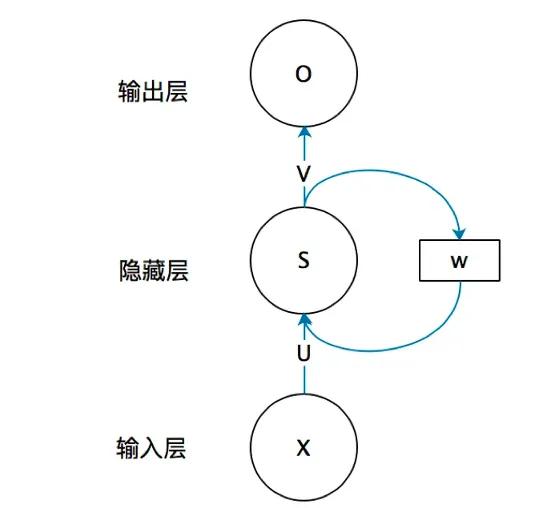
谷歌对NNLM改进,提出RNNLM,用内部隐藏状态,解决长距离依赖问题,目标是使用所有上文信息来预测下一个单词。
2013年谷歌提出Word2Vec
单词到向量,将上文提到的词嵌入发扬光大。从此开始,自然语言学习不在专注于建模语言模型,而是用语言模型学习单词的语义化向量。
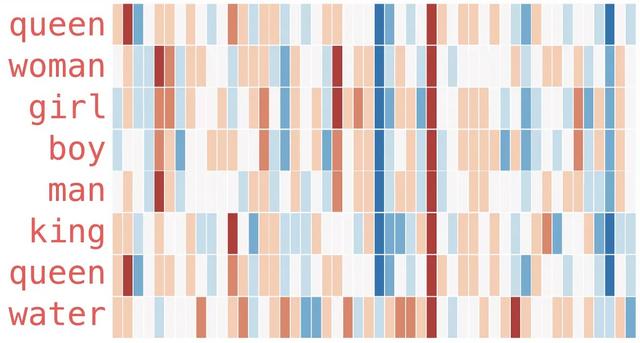
上图展示了,每个单词对应的语义化向量,每个向量中,会有不同的维度,每个维度表示了不同的语义。当两个单词在某维度上的语义相近的和话,那么他们的数值就会相近(图中为颜色相近),反之则差距较大。在这个时间点开始,也出现了万物皆可向量化的风潮。
2017年谷歌提出Transformer架构
2017年谷歌在论文《Attention is All You Need》中,提出了Transformer架构,也就是GPT的T。Transformer的出现,造就了一个关键的里程碑。论文中提到,一开始Transformer的目的是做机器翻译的,但也适用于其他机器学习。可能作者也没有想到,这个框架能够应用的那么广泛,可以说Transformer是目前绝大部分NLP(自然语言处理)的基础架构。
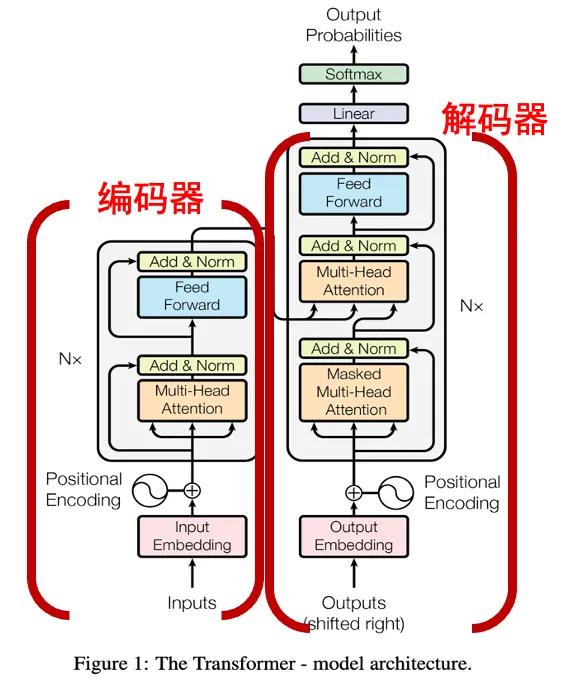
Transformer由编码器和解码器组成,像GPT系列用的是解码器,谷歌的bert系列用的是编码器,还有模型用的是编码器+解码器。目前看使用哪种形式更好,还没有一个定论,至少效果都是非常好的。
Transformer的核心概念是(多头)自注意力机制,多头是指有多个自注意力头,会从不同方面计算注意力。 Transformer的到来,带来了2个优点:
- 大大增强了并行计算能力
- 有效处理长距离依赖关系
其中并行能力的增强,也为大语言模型的到来,提供了技术基础。
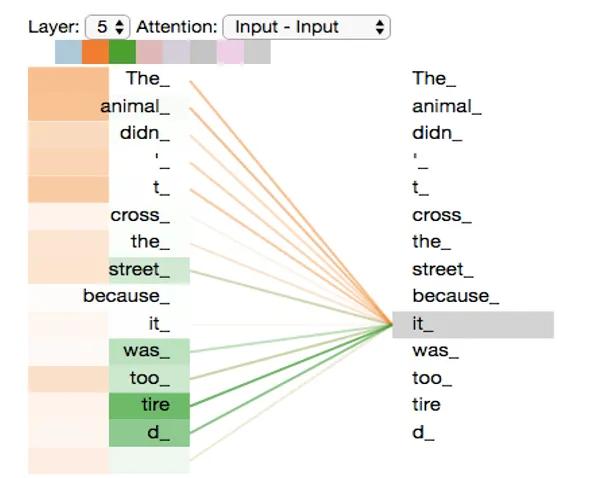
简单的看看自注意力的计算过程,上图以翻译为例,翻译的结果为“这个动物没有穿过这条街,因为它太累了。”,其中it,在计算的过程中,Transformer会将此单词和其他的每个单词都计算一个注意力,左边为计算结果,颜色越深关注度越高,两列表示有2个注意力头(从不同的方面计算注意力)。最终,合并多个注意力头的计算结果得出,animal和tired的注意力是比较高的,所以理解起来,就是it指代了这个动物太累了,而不是街太累了。
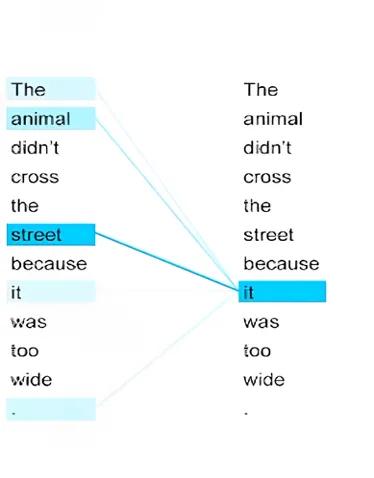
当我们改一个单词后会发现,计算出来的注意力,会变成street最高,所以改后的it,表示为这条街太宽了,所以动物才过不去。
这里可以说是,让机器学会从不同方面找到不同的关注点,通过数据间的关联性,来更好的理解、处理自然语言。
注意力头变化的过程可以参考这两个网站: https://alphacode.deepmind.com/ https://github.com/jessevig/bertviz#-quick-tour
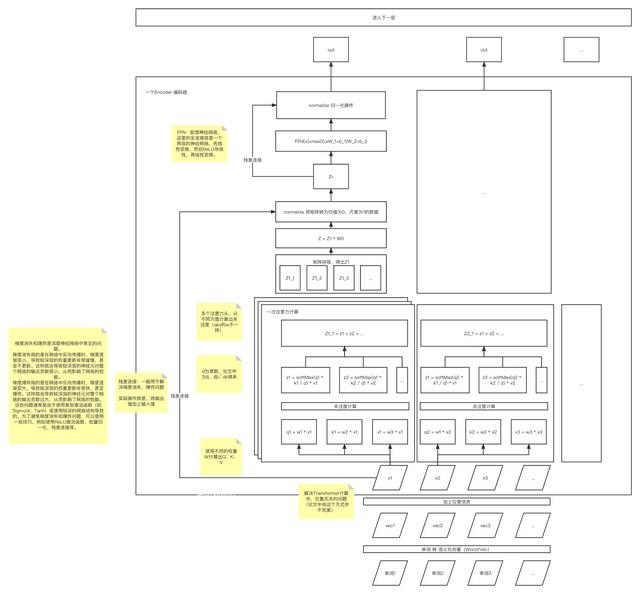
上图为Transformer架构的大致流程图
其他的
- 2014年发表的CNNLM卷积神经网络,在并行计算上其实已经做得很好了,但是对于长距离的依赖处理并不是很理想,其更擅长于捕捉局部的特征信息。
- 2014年发表的Seq2Seq,这个是基于循环神经网络的序列到序列学习模型,对于长距离依赖的处理很好,但是由于循环神经网络的串行计算,导致其计算会比较慢。不过Seq2Seq的结构也是,编码器+解码器,可以说,Transformer架构和Seq2Seq长得一样,只是内部的循环神经网络改成了其他的形式。
雏形
2018年openAI基于Transformer架构,推出GPT1
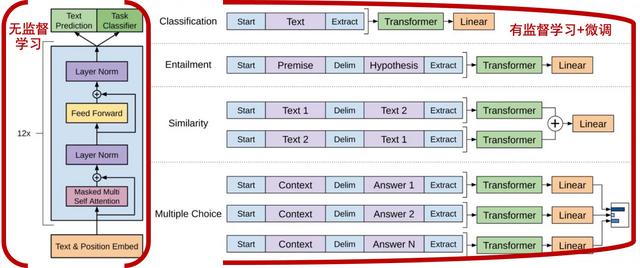
首先GPT使用到的是预训练模型,预训练模型主要分为两段训练,先在大规模未标注语料库预先训练一个初始模型,这第一步就是无监督学习。 然后再利用有标注数据对模型进行精调,第二步就是有监督学习并进行微调。这里就是GPT中的P。
在此之前,大部分语言模型是使用有监督学习,一个是需要大量有标注的数据,金钱、时间成本都非常高。另一个是训练的模型很难泛化到其他任务中,只能说是特定领域的专家。
GPT-1,放到未经微调的任务上,也会有一些效果,但远低于经过微调的有监督任务。也就是有一定的泛化能力,有很大的提升空间。
GPT-1可以说是跑通了大模型的训练范式,在这之后的大模型基本都是预训练的模式。
2019年,openAI推出GPT-2,使用无监督的预训练模型做有监督的任务
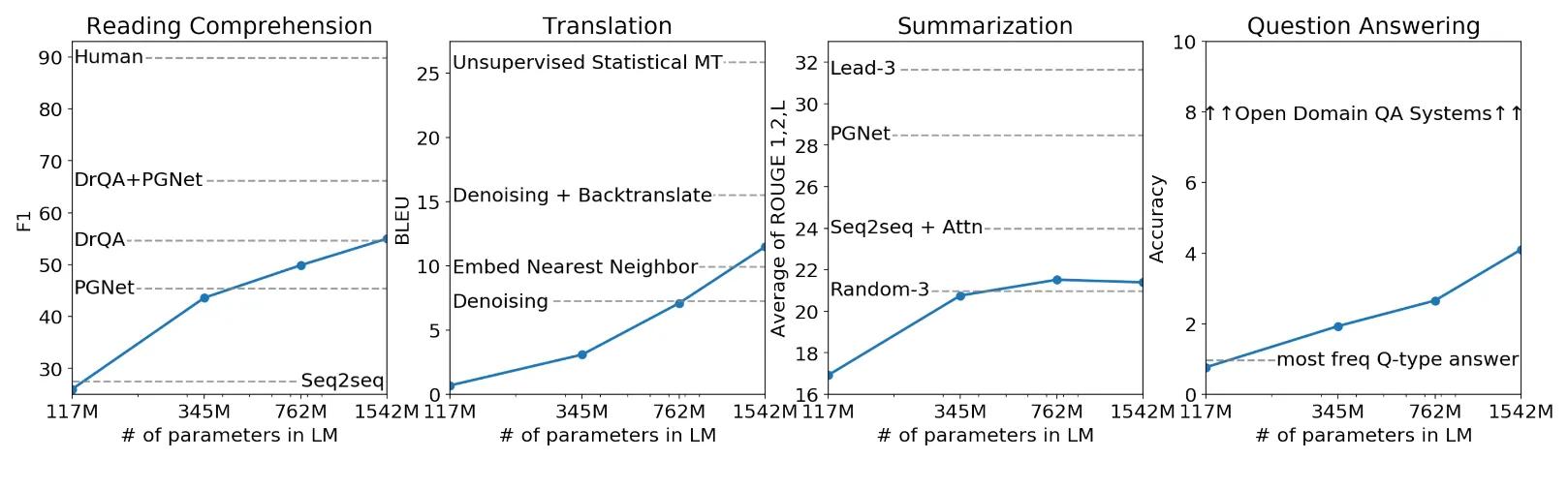
图中是GPT2在4个未经微调的任务执行的效果,折线为GPT2,虚线为对比的模型。可以看出,在模型足够大的时候,在某些任务下的效果已经超过了,有监督学习的模型。当然还是有些任务效果是比较差的,但总体是上涨的趋势,所以只要模型再大点,效果就会超过大部分的模型。
GPT-2在整体架构上并没有做太大的改动,主要是验证:当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
2020年,openAI推出GPT-3,超大的模型

从这个版本开始,GPT不在开源,openAI从此变成了closeAI。在GPT-2的基础上,openAI开始海量的堆数据,我们可以看看这个图,到GPT-3的时候,参数量和预训练数据量有了超百倍的提升。豪赌1200万美金,也可以说是大力出奇迹,效果确实很好。
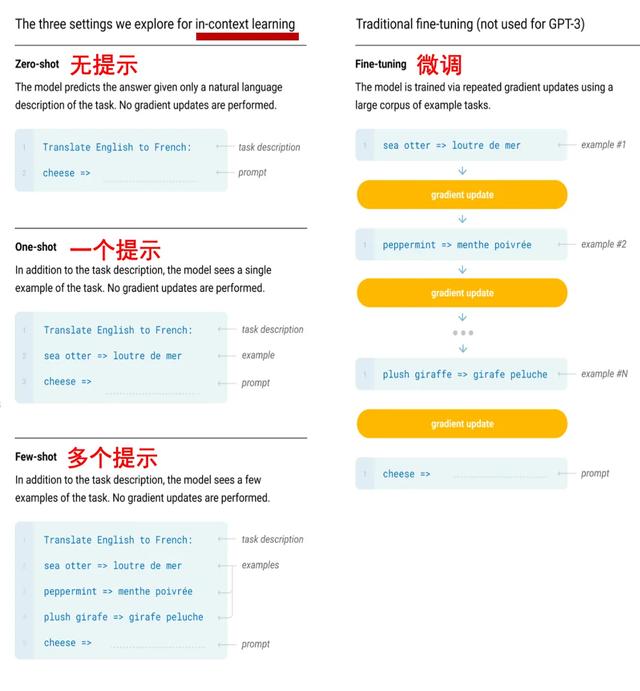
在GPT-3中引入了In-context learning(语境、上下文学习)概念,在这个学习的过程中,不会更新模型的参数。大概分为few-shot learning、one-shot learning、zero-shot learning。这个来自GPT3论文,以翻译为例,zero-shot就是不给提示,直接翻译,one-shot提供一个提示示例,few-shot提供多个。
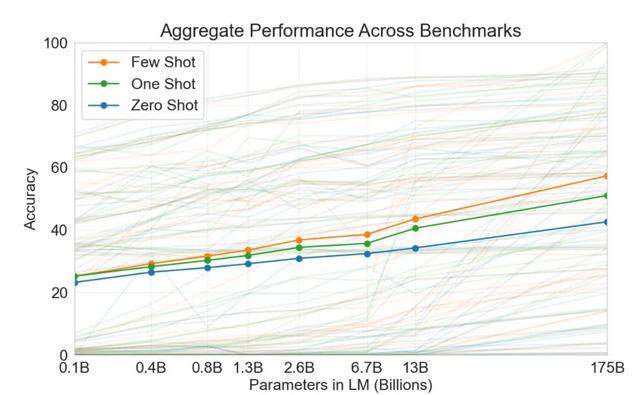
这是最终得到的准确性效果,可以看出在模型参数增大的情况下,准确性都会提高,并且给较多的提示,准确性会提升的的更多。这里的相当于在和GPT-3聊天的过程中,GPT-3能够理解上下文,根据上下文更好的完成当前的任务。
到这里GPT-3已经学习了很多很多内容,但是内容中有好有坏的,或者说会被内容带偏,例如种族歧视、性别歧视。所以这里直接商用的话,还是存在了一些问题。
今生
GPT3+RLHF ≈ GPT3.5 ≈ ChatGPT
openAI对GPT-3进行微调,衍生出GPT-3.5,3.5之所以叫3.5,是因为是基于GPT3,做了特定领域的微调后,衍生出新的模型。
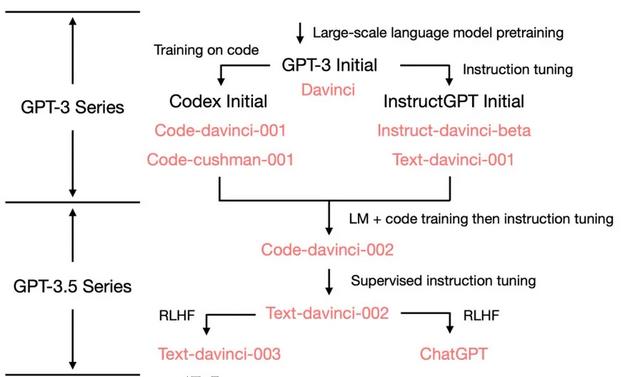
例如Codex 用作代码生成,instructGPT是ChatGPT的兄弟模型,经过RLHF(基于人类反馈的强化学习)微调得来的。
目前的话,我暂时没有看到官方针对ChatGPT的论文和技术说明,不过官方的文档是这么写的。一个是 ChatGPT是instructGPT的兄弟模型。第二个是ChatGPT从GPT3.5的一个模型微调过来的 从官方的说明上可以看出,InstructGPT约等于ChatGPT,ChatGPT可以说是针对聊天场景的更高级版本。
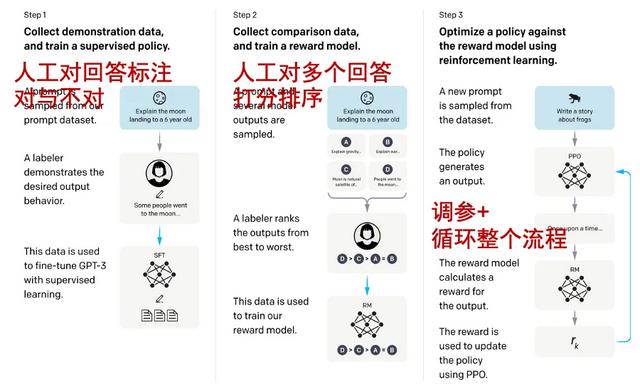
这个图是InstructGPT论文中给出的炼丹过程,也就是RLHF(基于人类反馈的强化学习),大概得意思是,基于GPT3,第一步提一些问题,并人工对回答进行标注,标注对与不对,然后训练出SFT模型。第二步基于SFT,提问,然后回复多个答案,人工对多个答案进行打分,得出4个答案的得分排序,得出RM模型,就是奖励模型。第三步就是利用PPO算法继续调整模型的参数,让他生成的答案可以达到RM模型中更好的答案。最后循环这个流程,得出的就是instructGPT。
这里我们可以知道,GPT-3进行微调、强化学习后,得到了instructGPT。而ChatGPT也是用的这样的方法训练出来的。
GPT4
到现在的GPT-4,openAI这次发布的GPT-4技术报告,没有讲到太多的技术细节,也没有说模型具体是怎么训练的,重点表达了
- GPT-4是个输入多模态的模型,
- 训练的方式和GPT3.5类似,也是大模型+RLHF(其实在大模型堆料出来后,已经有了一定的效果了,而RLHF不是一定可以提高模型的准确性,但这里可以让结果更符合我们想要的,例如更安全、更像人类语言)。
- 效果有多么多么的强。
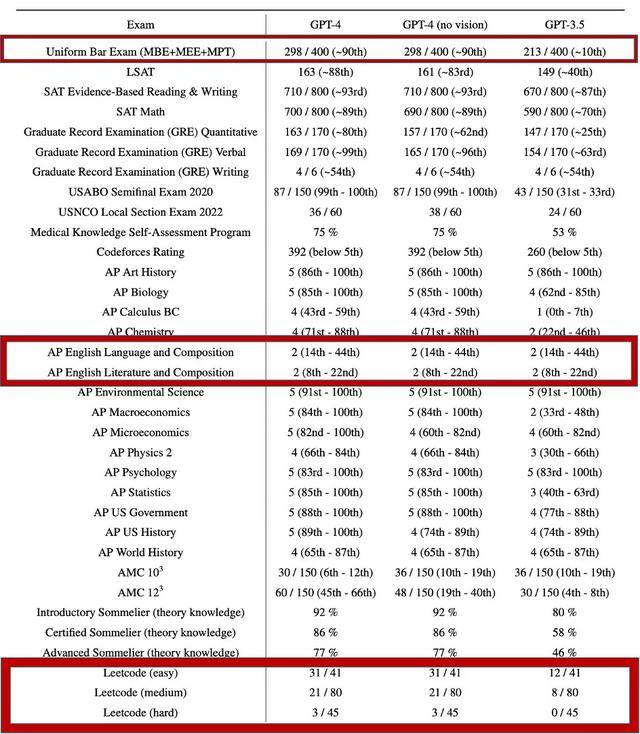
这里是用GPT-4进行各项人类考试的分数,左边两个是GPT-4,右边的是3.5,第一行就是在网上热议的律师证书,括号中的~90就是打败了参与考试90%的人。最下面我们可以看到leetCode考试,效果其实挺不错的,虽然不是很突出,但是和正常人差不多了。
还有一个更有意思的,GPT-4在参加美国高中语言、文学考试的得分,其实都不高。这可能和我们所认知的不太一样,ChatGPT可以生成一段一段的文本,讲得都很有道理,但是用多几次就可以发现,讲得很多都是空话、大话,没有自己的观点,也就是一本正经的胡说八道。
ChatGPT的发展,很关键的一点就是大力出奇迹,说到大力出奇迹,那就要说一下大模型的涌现能力。
涌现能力
涌现能力是指,在模型达到一定规模的时候,特定领域的效果会大大提高,甚至会出现之前没有的能力。
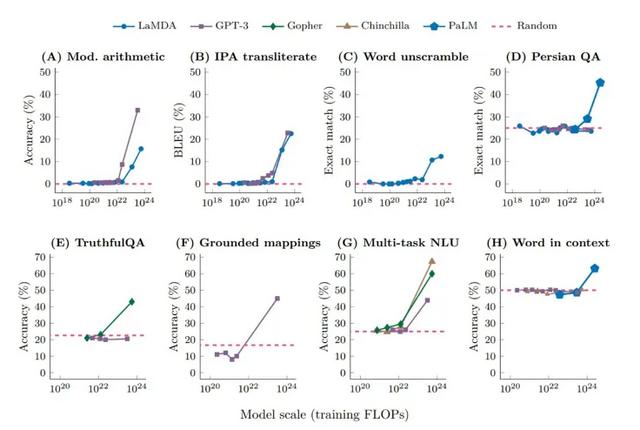
从这个图中是5个语言模型的8种涌现能力,可以看出,在某一点前,效果会比较一般,或者没有。但模型到达一个阈值时,效果就得到了大大的提升。

在ChatGPT中,有个思维链能力,如图所示,直接提问,ChatGPT无法给出正确的答案,但在提问前,先教GPT怎么做题,然后再问问题。此时ChatGPT会体现出举一反三的能力。
目前还不清楚思维链能力是如何出现的,猜测是和代码训练有关。因为最初的 GPT-3 没有接受过代码训练,不能做思维链。而经过Codex的训练后就有了思维链的能力。其他大模型也是这样(有人说,代码编程需要较强的推理能力,所以学习代码之后,思维链就出来了。作为程序员的我,挺赞同这个解释的,毕竟我这么聪明)。
对涌现能力,暂时没有一个公认的解释。有一个合理的假设,就是,更多的参数和更多的训练能够确保更好的记忆那些有助于各类任务的世界知识。
当然涌现能力也有可能带来一些负面的效果,例如模型大到一定阈值,突然就会讲黄段子,一言不合就开车。所以大模型就得练,好模型就得调。
ChatGPT评价
首先说一下优缺点
优点:
- 效率高:相对于人脑,可以在短时间内处理大量的信息。算力上有着绝对的优势。
- 应用广泛:无论什么行业,都能运用上,能作为各行各业的提效工具。
- 高级自然语言处理能力:具备强大的自然语言理解和生成能力,能够生成流畅、自然的文本,使与人类的交流更加顺畅。

这里还是去问了一下TChatGPT,上面是GPT3.5的回复,可以发现红线的回答是有问题的,都是乱讲的。

这个是GPT4的,回答上,算是合理,有理有据。(这里也试了鲁迅打了周树人的问题,GPT3.5确实有问题,而且怎么都无法纠正,GPT4中回复是正确的)
缺点:
- 准确性:对于ChatGPT来说,学了很多,但目前还不能保证所有内容都是正向或正确的。有时候会给出看似合理,但是错误的答案,此时往往就会误导用户,造成负面影响。这也是大家所说的幻觉问题
- 安全性:前段时间也很多人在怀疑ChatGPT的安全性问题,虽然官方说是安全的,但是这里我还是要打上问号,所以大家在使用的时候一定要注意个人信息、机密信息的泄露
- 缺乏情感、个性化:就像那谁说的,ai只有芯,而人有心。
抛开这些来说,ChatGPT确实迈出了一大步,这一大步可以说是意料之中,也可以说意料之外。因为这一天终会到来,只是没想到突然被加速了。
突然又有一个问题
本来我以为GPT4完善的很好了,但是在我收集各大语言模型的数据时,GPT4又开始忽悠我了。
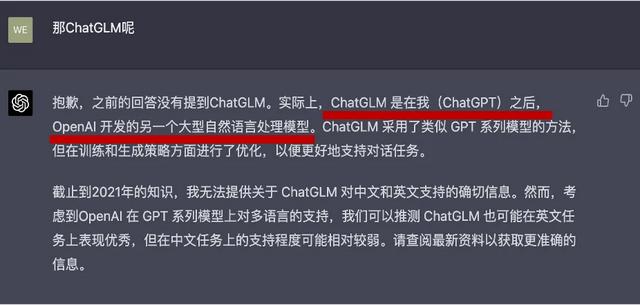
这里问了ChatGLM,ChatGPT一本正经的说是OpenAI开发的模型,而且讲的这么合理,如果我不是事先知道这个模型,大概率会被骗。实际ChatGLM是国内清华团队做得语言模型。所以实际使用的时候要是要注意不要被忽悠了。
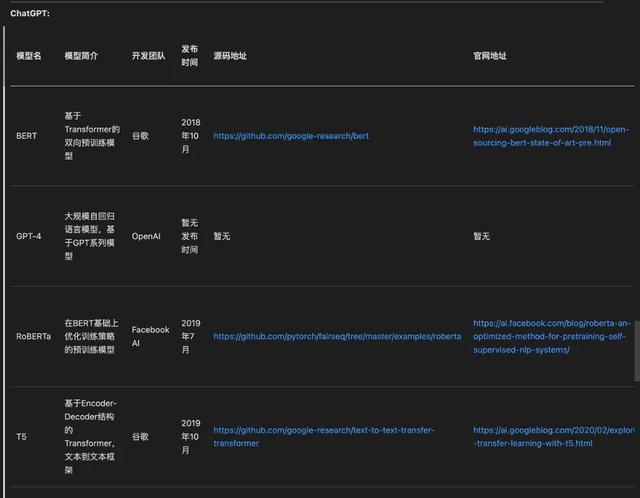
当然最终做出来的表格还是挺不错的,ChatGPT可以输出md的表格格式。
个人评价
首先在技术层面上,我个人认为谷歌还是那个谷歌,技术上的贡献比OpenAI会更大,例如Transformer、Bert。
但是在应用和效果上来说,OpenAI的GPT会做得更好,现在市面上,有很多大语言模型,很多都是对标GPT,都说达到GPT的效果,比GPT强之类的,但是实际用起来就那样吧。GPT在目前来说,确实效果算是最强的了。
附录
相关论文地址:
- NNLM: https://jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
- RNNLM:https://www.microsoft.com/en-us/research/wp-content/uploads/2011/12/ASRU-Demo-2011.pdf
- Word2Vec: https://arxiv.org/pdf/1301.3781v3.pdf
- Transformer: https://arxiv.org/pdf/1706.03762.pdf
- GPT-1: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
- GPT-2: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
- GPT-3: https://arxiv.org/pdf/2005.14165.pdf
- 思维链: https://arxiv.org/pdf/2201.11903.pdf
- 思维涌现: https://arxiv.org/pdf/2206.07682.pdf
- instructGPT: https://arxiv.org/pdf/2203.02155.pdf
- GPT-4: https://arxiv.org/pdf/2303.08774.pdf
- RLHF: https://arxiv.org/pdf/1706.03741.pdf
- PPO: https://arxiv.org/pdf/1707.06347.pdf
参考文献
- The Illustrated Transformer
- The Illustrated GPT-2
- 深度学习的数学
- 一文搞懂RNN(循环神经网络)基础篇
- The Illustrated Word2vec
- GPT Lineage
- ChatGPT 调研报告
- OpenAI GPT 和 GPT2 模型详解
Transformer架构流程图
https://doc.weixin.qq.com/flowchart/f3_ABEARAbNACcjNm5EvCvTSOnGZ6I3O?scode=AJEAIQdfAAo6jeGa6yABEARAbNACc
GPT的解码器
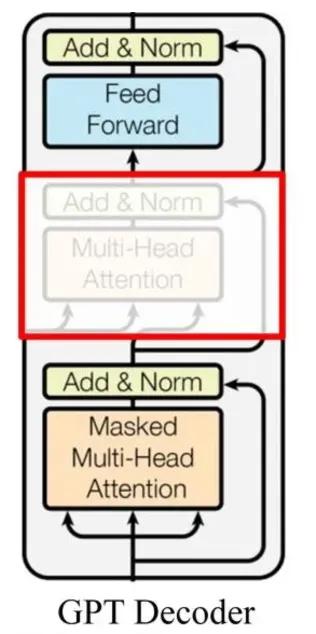
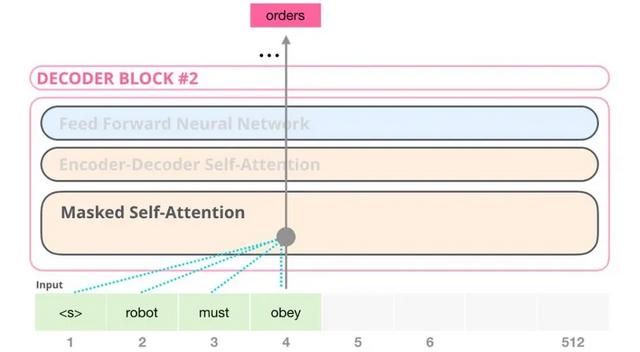
GPT的解码器和Transformer的解码器也有点不一样,去掉了中间那部分,毕竟没有了编码器的输入
GPT的词嵌入长度
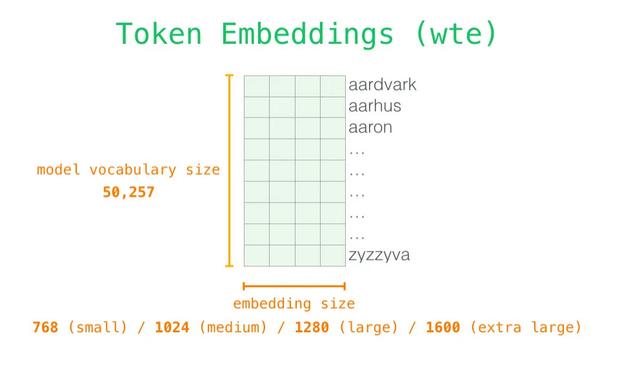
Transformer中为512(d_model)
生意营销3大宝:彩铃、定位、认证,一个也不能少,如有需要,添加 微信:xnc528 备注:3
如若转载,请注明出处:https://www.clzz8.com/51406.html
相关推荐
-
情侣视频的时候做什么,情侣要怎么增进感情?
情侣之间增进感情的3个小动作,如果每天能够做到,关系会变得更加的亲密。男女之间的感情,是需要有仪式感的。正是这样的仪式感,可以加深两个人之间的感情记忆,让两个人爱得越来越刻骨铭心。…
-
如果你精神内耗很高,总爱胡思乱想,强烈建议你阅读收藏本文?怎么对渣男精神折磨!
前段时间,网上“反炸APP”很火,各地公安部门拍了很多视频,鼓励大家下载这个软件,防止被骗财。 然而有人说,世界上最大的敌人是自己。对于精神内耗这种“自我PUA高手”,下载反诈AP…
-
教法从无到有、从有到无
我觉得教学的最底层逻辑就是教师通过努力把教材中的“知识与技能”传递到学者的头脑里面;学生通过努力把接收来的“知识与技能”进行“化为己用”。 在教师和学生的努力过程中,就会产生各种各…
-
爸爸带儿子到售楼处找妈妈,孩子盯着沙盘不动,走近一看无法淡定
随着宝宝的年龄增大也越来越难大。这时候妈妈们都开始感叹,在怀孕的时候想着宝宝赶紧生下来,可是等宝宝生下来后都想着还不如在肚子里的好,出来太烦人了。孩子太调皮,特别是孩子到了四五岁的…
-
2023最新儿童身高标准发布,你家孩子达标了吗?
点击右下角“关注”我噢~ 作者:川妈 春天是万物复苏的时节,也是孩子长个子的黄金季节。 据说,这波生长高速期会一直由初春持续到夏初,平均速度比秋冬季节要快 2 – 2….
-
vigg是什么档次的牌子,vigg这个牌子档次如何?
不知道你们有没有这样的感觉,冬天的时候还能通过叠穿衣服来增加穿衣的精致感,但在露肤度高的夏天,真的很难靠穿搭出彩,倒不如在配饰上下功夫。 甚至配饰于我而言,更多的是让我看起来跟绝大…
-
台湾什么时候能回到祖国怀抱
叶耀鹏,台湾时事评论员,原民进党创党元老,如今是两岸统一的坚定支持者。他在今日头条有自媒体头条号《叶耀鹏台湾》,粉丝量达到211.3万。 最近看到他的一条视频,标题是《为何两岸统一…
-
世界上最冷漠的花的花语,荼靡花花语是什么?
人无闲情,生活无趣:我把我的梦种成蓝雪花文‖杨静 图‖网络 蓝雪花属多年生直立草本,可播种,也可扦插,分株法繁殖。蓝雪花的花语是冷淡、忧郁,送给朋友希望你能感受到我热烈炽热的爱。相…
-
婚后多年怎么维持增进夫妻感情,增进夫妻感情的方法
为一位85后宝妈,没结婚前觉得以后有了宝宝在照顾好宝宝的同时一定要维护好夫妻之间的感情,对于宝宝最好生长的环境就是爸爸妈妈相亲相爱,宝宝才会快乐的长大。事实是产后一段时间内矛盾激发…
-
100海龟汤问题及答案 点了个海龟汤(100海龟汤问题及答案豆瓣)
你玩过海龟汤吗?,我相信有些人玩过,别问为什么,今天脑子抽风,来写文章( ̄▽ ̄)因为今天我看我姐她们玩海龟汤,我很羡慕,然后我就自己给我们班同学建立一个玩海龟汤的小群,但是因为玩不…
