
下面这个网站页面,列出了很多AI网站,但是是以图片方式列出,点击图片会跳转到网站。怎么能把这些AI网站名称、AI网站网址自动爬取下来保存成excel文件呢?


首先,在chrome浏览器中点击右键,点击inspect,可以查看到每个图片超链接的网页源代码
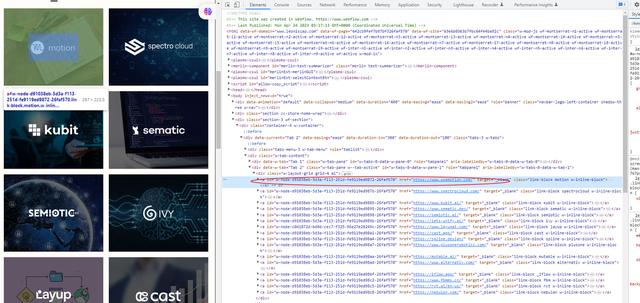
可以看到,网址在href属性值里面,网站名称在alt属性值里面

<div class="grid-image-wrapper">
<img width="800" loading="lazy" src="https://uploads-ssl.webflow.com/63e6b0363b7fbc64fe4ba92c/63f1777cc167269e00510ad4_motion%20white.png" alt="Motion logo"></div></a>
但是,alt属性值后面多了一个logo,所以获取到这个属性值后要去掉logo这个串字符。
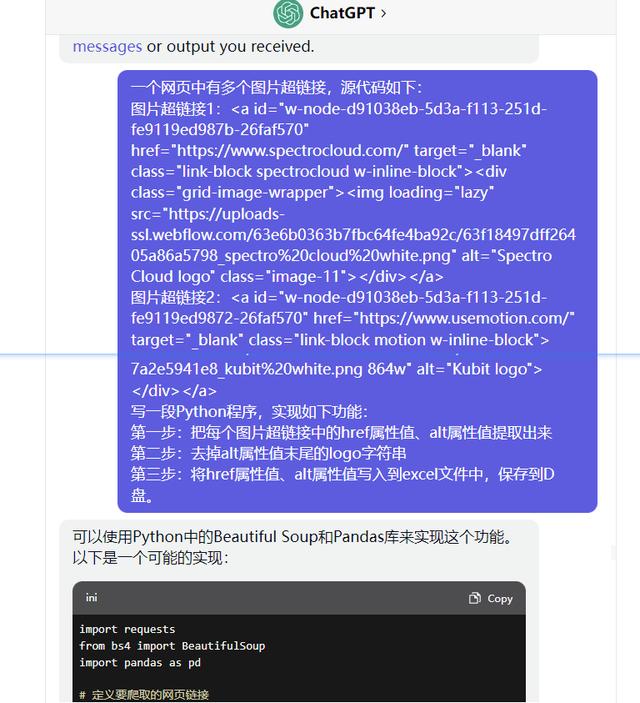
然后让chatgpt写一段代码
复制粘贴到Visual Studio Code中运行,显示程序运行错误,推测应该是Python安装环境的问题
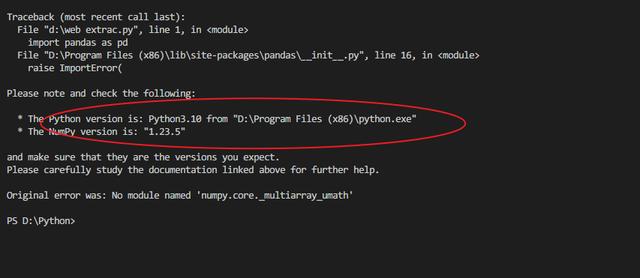
于是,安装Anaconda3,创建虚拟环境
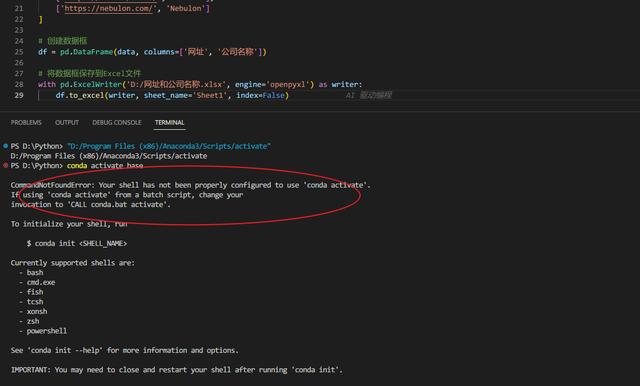
虚拟环境创建成功了,但是无法激活,显示:
CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'.
If using 'conda activate' from a batch script, change your
invocation to 'CALL conda.bat activate'.
To initialize your shell, run
$ conda init <SHELL_NAME>。
试了多个方法没成功,最后修改运行终端为command prompt,终于成功。
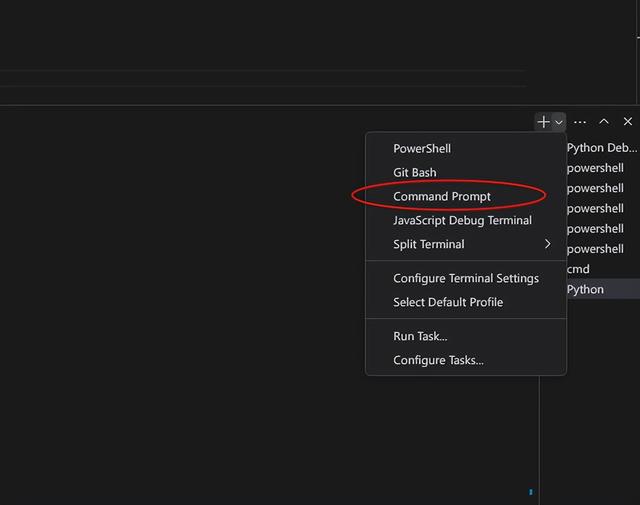
这时候程序没有报错,但是创建excel文件不成功。把出错信息丢给chatgpt,让它找解决办法。
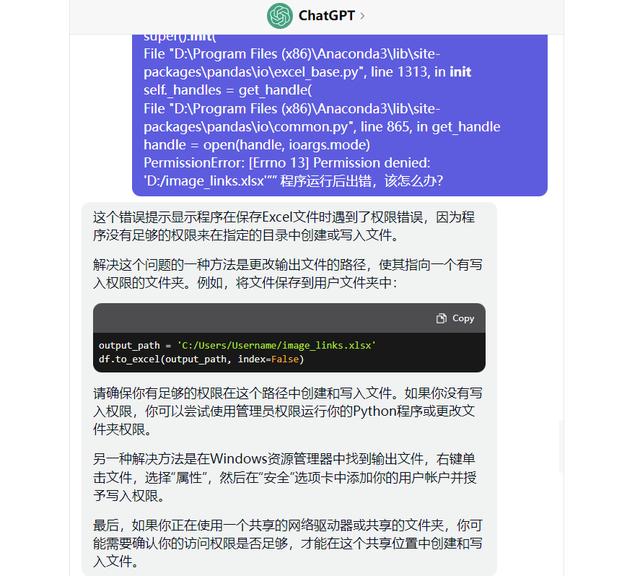
尝试了chatgpt推荐的几个方法,没有成功。
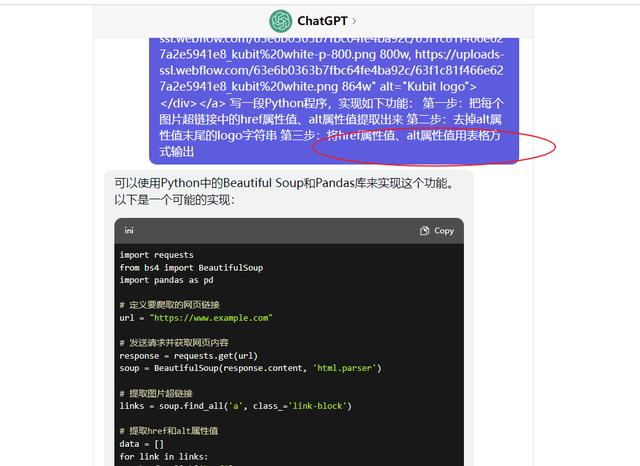
放弃,于是让chatgpt不生成excel文件,只输出一个表格。
终于成功!
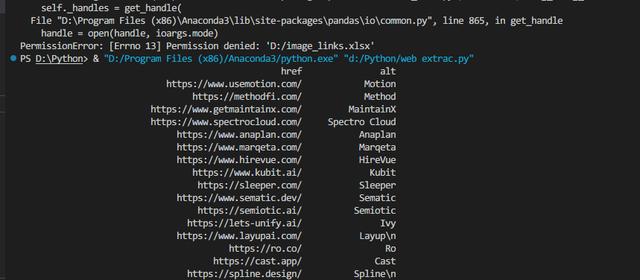
但是,有一个问题,我只想要AI相关的网站信息,但是这个程序把web3和其他网站信息都爬取下来了。
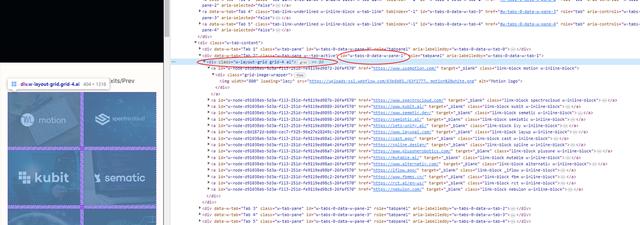
查看网页源代码,好像没有分成多个网页,所有这些网站都在一个html页面。那就让程序只爬取包含AI网站的div里面内容,修改chatgpt提示词:
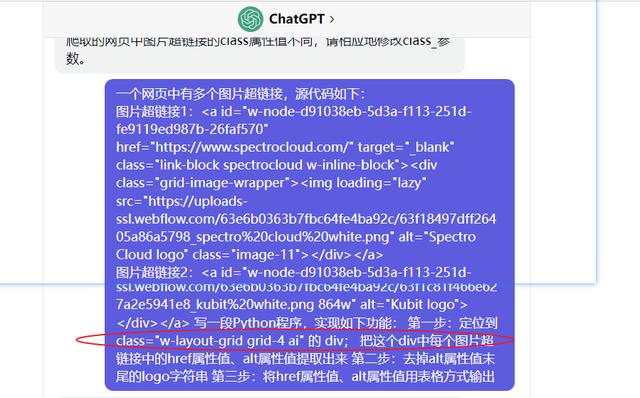
然后在虚拟环境中跑这个Python程序
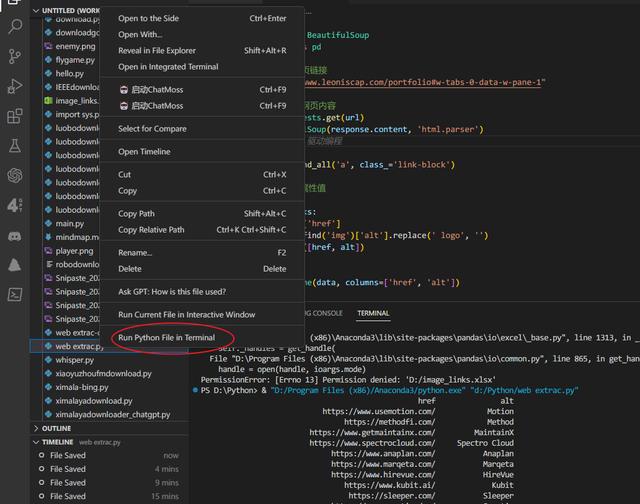
终于大功告成,爬取到真正想要的数据信息。
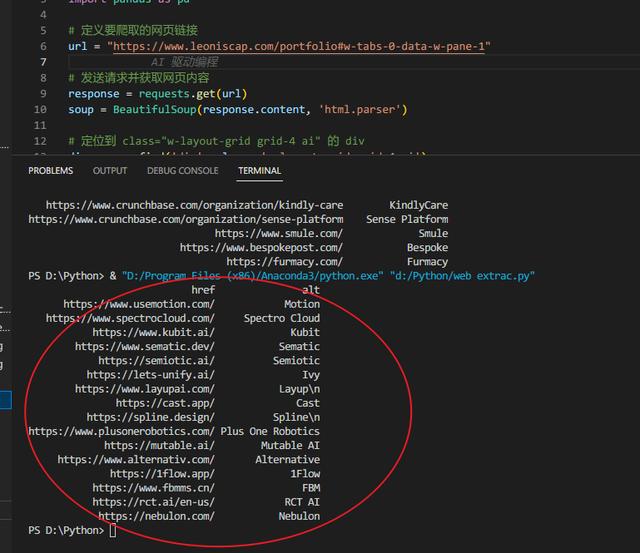
不过,这些表格信息复制到excel里面就乱了。
再尝试让chatgpt整理这些信息然后写入excel表格:
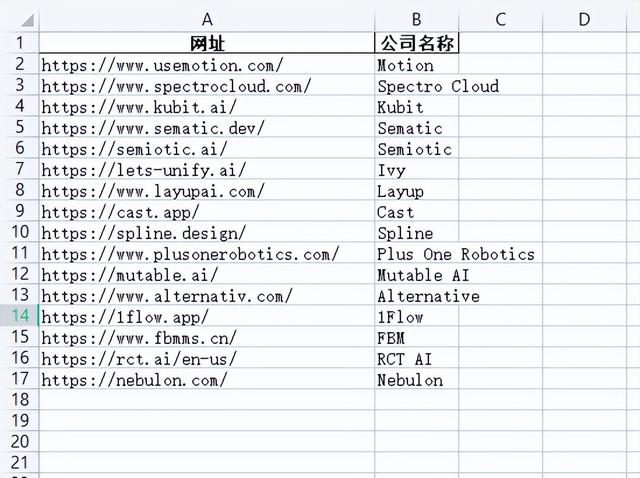
这次运行成功,成功创建如下excel表格,完美的将网页中的信息爬取和整理好了。
一些经验总结:
Python编程一定要装Anaconda3,用虚拟环境来运行。很多时候出错,都是环境配置有问题。用虚拟环境可以完美解决这个问题。
多次迭代优化。由于现实中的情况复杂多变,很少情况下程序一次就跑通,要根据每次返回的错误信息去针对性的修改完善。
如果ChatGPT不能一次性完成设定的目标,就分解成两个甚至多个任务,然后一个个的完成。
生意营销3大宝:彩铃、定位、认证,一个也不能少,如有需要,添加 微信:xnc528 备注:3
如若转载,请注明出处:https://www.clzz8.com/44784.html
相关推荐
-
黄沙4行业精选的企业彩铃广告词模板
黄沙4行业精选的企业彩铃广告词内容模板 我们为大家精选了几个优质的彩铃广告词内容模板范本,以满足朋友们的需求! 您好 欢迎致电利和工程设备租赁有限公司,本公司长期对外…
-
唐家三少娶了年轻女学生是真的吗唐家三少娶了年轻女学生是真的吗小说!
如果问你们最熟悉的网文作者是谁,我想很大一部分人,脑海中都会浮现一个名字-唐家三少,其笔下的《斗罗大陆》一经问世,更是创造了多项记录,至今无人能打破,而《斗罗大陆》也是系列最多的网…
-
烧烤店行业精选的企业彩铃广告词模板(2)
烧烤店3行业精选的企业彩铃广告词内容模板 很多朋友一直想有个好的彩铃广告词内容模板范本,今天给大家精选了几个。 1、您好 欢迎致电圣地情中餐烧烤店 本店位于延安市凤凰…
-
女人到了中年,会穿“米色”才更温柔高级!看日本女人这样穿多美
所有的服装配色当中,大家最中意哪一款颜色呢?相信每个人都有自己喜欢的颜色,比如粉色的娇嫩、红色的鲜艳、橙色的活力以雾霾蓝的温柔,世间色彩千千万,今天就要跟大家聊一聊“米色”! 相比…
-
如何用ChatGPT写出惊艳的文章?吴恩达教你提示工程的秘诀!
今天我要给大家讲一个神奇的东西:ChatGPT。你可能会问,ChatGPT是什么鬼?它是一种能够自动写文章、说话、唱歌、画画的超级机器人吗?不不不,它不是机器人,它是一种大型语言模…
-
装修设计施工行业精选的企业彩铃广告词模板
装修设计施工行业精选的企业彩铃广告词内容模板 很多朋友一直想有个好的彩铃广告词内容模板范本,今天给大家精选了几个。 1、彰显不凡品质,缔造经典空间,欢迎致电云县**装…
-
都结婚怀孕了,怎么还住娘家
你们结婚怀孕是住娘家还是婆家呢?大家肯定说当然住自己家了。 住婆家那得看公婆的脸色过日子,住娘家时间长了也不合适呀。是的,我现在就是处于这样一个尴尬的境地。因为没有买房,没有自己的…
-
风水引擎,风水学入门知识住宅风水?
他是香港巨富明星们的御用风水师 在李嘉诚办公室大摆“风水局” 后用一句话就负债3亿的杨受成逆风翻盘 病重之际 更是被李嘉诚和杨受成争着出医药费 他就是陈伯 01在中国大多数年轻人提…
-
装饰设计行业精选的企业彩铃广告词模板(2)
装饰设计5行业精选的企业彩铃广告词内容模板 很多朋友一直想有个好的彩铃广告词内容模板范本,今天给大家精选了几个。 1、您好,欢迎致电林根装饰设计工程有限公司,本公司专…
-
男人的这三种婚外情,最难结束,原因不在小三都在出轨男人身上
虽然佳鑫一直说,大多数婚外情只要方法用对,都能够解决。 但是并不代表,所有的婚外情解决的过程都是一帆风顺的。 很多婚外情能解决,但是不好处理,并不是因为小三段位高,问题出在出轨男人…