
2023年3月23日OpenAI官方宣布ChatGPT即将支持Plugin模式。这是一种用插件的方式来解锁ChatGPT的能力,包括让ChatGPT可以浏览网页、从本地商店订购食材等。

但是,这个模式一直是以非常有限的方式邀请极少部分用户来内测。尽管申请人数众多,但是真正使用的案例非常少!今天,沃顿商学院教授Ethan Mollick在推特上公布了自己收到了ChatGPT内测邀请,并使用它的代码解释器(Python Interpreter)插件让ChatGPT针对一份excel数据完成了非常专业的数据分析的工作。
在这个实例中,大家看到未来我们甚至不需要给ChatGPT下达专业的分析指令即可让ChatGPT对一份纯粹的数据给出一份十分专业的分析结果和可视化结果。本文将带大家看一下这个案例,这也许是未来ChatGPT强大能力的一个小案例,但可以让我们看到大语言模型的未来不可估量!本文来自DataLearner官方博客:MBA与数据分析师危矣?最新内测版本的ChatGPT已经可以针对excel自动做数据分析和异常分析了! | 数据学习者官方网站(Datalearner)
- 一、上传给ChatGPT的数据简介
- ChatGPT的数据可视化与描述化分析10个投资最多的区域条形图用散点图对比平均交易额和每笔交易的平均资产额用直方图展示所有MSA的交易数量分布图
- ChatGPT对数据的回归分析和模式发现投资股权总数和交易数量之间的回归分析平均投资额度和每笔交易平均股权之间的回归分析公司数量和每个公司平均股权之间的回归分析
- ChatGPT对前面回归结果的异常值分析
- 总结
一、上传给ChatGPT的数据简介
Ethan Mollick上传的这份excel数据没有任何描述,仅仅包含列名和每一列的值。从给出的截图看,这份数据主要是美国不同区域中风险投资(Venture Capital,VC)的统计结果,包括投资的公司数量、每个VC平均投资股权数量、交易金额等。但是,原本的excel只给出了如下列名和每一列的数值:
|
列序号 |
列名 |
|
1 |
Company MSA |
|
2 |
No. of Deals |
|
3 |
No. of Companies |
|
4 |
No. of Firms |
|
5 |
Avg Equity Per Deal (USD Mil) |
|
6 |
Avg Equity Per Company (USD Mil) |
|
7 |
Avg Equity Per Firm (USD Mil) |
|
8 |
Avg Deal Value (USD Mil) |
|
9 |
Sum of equity Invested (USD Mil) |
|
10 |
Sum of Deal Value (USD Mil) |
从这些列名看,如果你是专业的VC领域人员应该可以理解大部分内容。但是,即便如此,如果你不熟悉英文环境,像MSA这样的名词可能也很难理解。然而,就是这样一份数据,没有任何其它的提示,ChatGPT却可以读懂,并给出了自己的理解结果:

ChatGPT根据这份数据的内容,给每一个列名都做了解释,甚至是MSA这样的名词也给出了具体的含义:即Metropolitan Statistical Area(MSA),是指人口超过50,000的城市及其周边地区的统计区域。
其实,上传了这份数据之后,Ethan Mollick教授就问了三个问题:
- Can you do visualizations & descriptive analyses to help me understand the data?
- Can you try regressions and look for patterns?
- Can you run regression diagnostics?
这三个问题都是非常描述化的结果,没有任何具体的指令,接下来,我们分别看看ChatGPT给出了怎样的回答。
ChatGPT的数据可视化与描述化分析
上传完数据之后,Ethan Mollick教授的第一个问题就是让ChatGPT对这份数据做一些可视化和描述,来帮助他理解这份数据。然后,ChatGPT就根据数据内容,给出了每一列的含义解释(即上面一节的截图)。接下来,ChatGPT首先根据列名分析的结果,给出了3个可视化的分析建议:
10个投资最多的区域条形图
即根据投资资产展示投资资产最多的10个MSA。
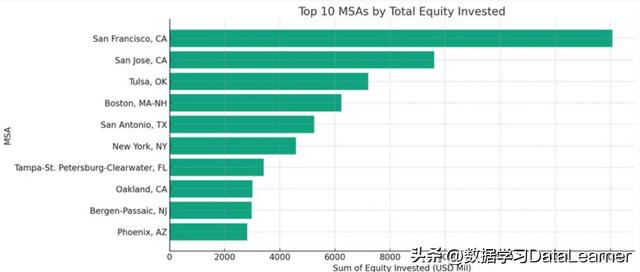
需要注意的是,这个分析结果的前提是需要对MSA分组求和投资资产,然后再根据求和结果进行排序,选择做多的10个。而这些都是ChatGPT来完成的。
用散点图对比平均交易额和每笔交易的平均资产额
这是将每一个MSA单独统计,计算它们的平均交易数额,以及每一笔交易的平均资产额度,然后把所有的区域用散点图展示。
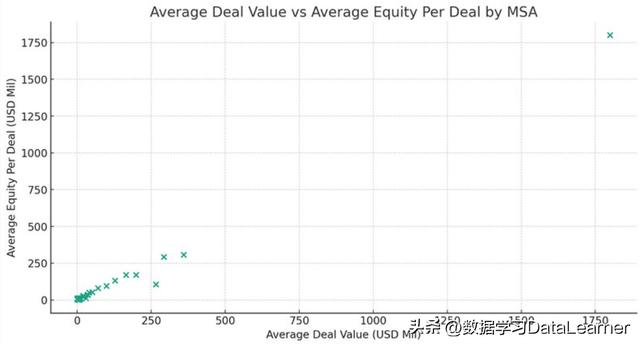
这是一个十分有趣的思路,展示的信息十分丰富,不仅可以从图中看到一个十分异常的区域(右上角),也可以看到每一个区域的每笔平均交易资产和平均交易数额的关系,应该是十分优秀的展示逻辑!
用直方图展示所有MSA的交易数量分布图
这里展示的是交易数量的分布,可以看到不同交易数量的MSA有多少个。
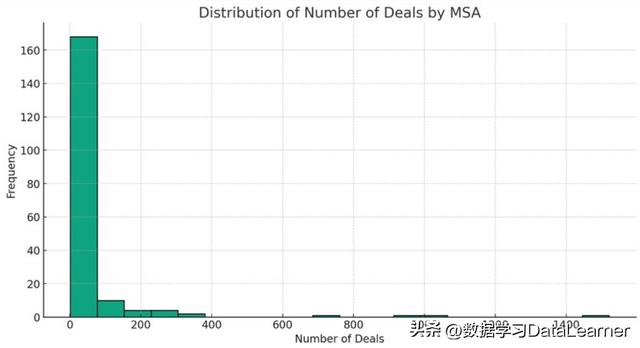
这里可以看到,大部分MSA的交易数量都在100以内的。从这里大家也可以推测这份数据的规模,大概在几万条(100的交易数量区域160多个)。
以上就是ChatGPT根据之前的数据做的3个可视化建议。我觉得,这三个可视化结果比我专业很多。至少第2个图的结果我很难想到。
不过,需要注意的是ChatGPT并不是直接给出这三个结果。还给出了这三个图中的过程处理。尤其是关于错误处理的信息。例如,ChatGPT在处理资产投资总额的时候发现对Sum of equity Invested处理出错了,提示类型错误,所以ChatGPT又强制将这个列转成了数值类型之后再去做可视化。

随后,ChatGPT还对这份数据做了描述总结。
ChatGPT对数据的回归分析和模式发现
Ethan Mollick教授的第二个问题是让ChatGPT对这份数据做回归分析并总结一些有趣的结论。
这个问题其实十分宽泛,只是有个回归分析的方向。ChatGPT首先就说明了如果做回归分析需要先识别依赖变量和独立变量。显然,这里有很多种可能,于是ChatGPT给出了3个回归分析:
投资股权总数和交易数量之间的回归分析
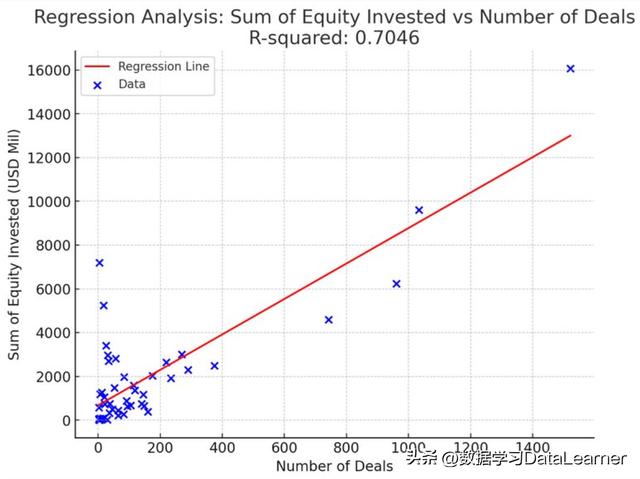
ChatGPT还给出了这个回归分析的结论,即总的股权投资数量和每一个MSA的交易数量正相关,R-squared值是0.9569,表示这两个数值之间强相关。
平均投资额度和每笔交易平均股权之间的回归分析这份回归分析结果依然是正相关结果,但是R-squared结果是0.7886,大约是中等到高程度的相关,意味着更高股权数量投资可能会有更高的交易金额。
公司数量和每个公司平均股权之间的回归分析
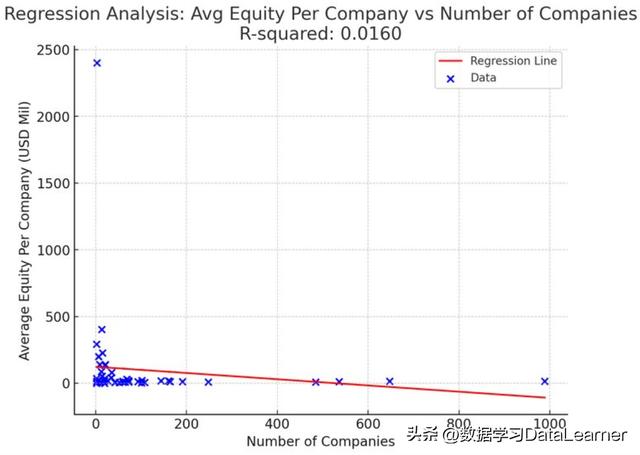
这个结果的R-squared是0.0557,显然二者之间没有相关性。
如前所述,其实这个过程中,ChatGPT还给出了处理过程中对于缺失值的处理,真的是太智能了!
ChatGPT对前面回归结果的异常值分析
Ethan Mollick教授最后一个问题是让ChatGPT对前面的回归分析做异常结果的分析。
ChatGPT直接使用残差图来评估异常值的影响。并给出了三个步骤:
- 对每个回归分析结果进行残差图展示,识别异常结果
- 计算每一个回归分析结果的Cook’s Distance(库克距离)识别有影响力(influential)观测结果
- 回归诊断和关键结果评估,例如Durbin-Watson统计、方差膨胀因子(VIF,Variance Inflation Factor)等分析
下图是展示的一个分析结果:
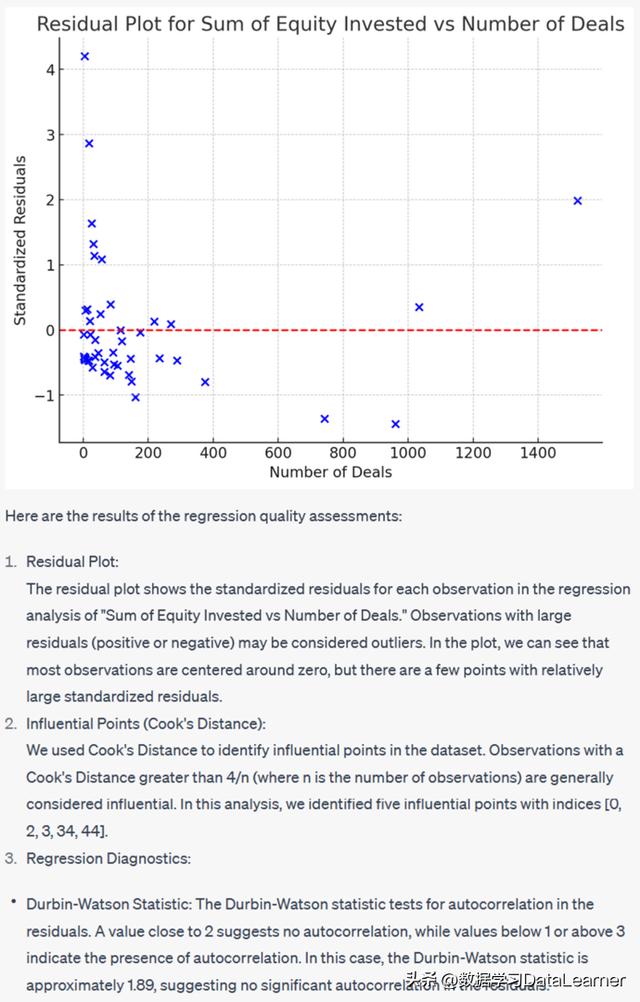
可以看到,ChatGPT给出了每一个步骤分析的指标结果和结论,真的是很专业,至少这些指标我都不知道!
总结
需要大家注意的是,前面这些长篇的分析结果都是基于上述三个问题和数据得出来的。然而,问题都很宽泛,数据也缺少上下文信息。但是,就是这样的数据和问题,ChatGPT基于自己的数据理解能力和代码生成能力,凭借Python解释器插件展示了分析的结果和结论。真的是太强大了。按照这个数据分析的水平,现阶段大多数的报表系统、洞察系统可能都面临极大的压力。所谓的数据分析师岗位和市场洞察岗位可能真的是继“画图工作者”的下一个被AI打击的对象了!
生意营销3大宝:彩铃、定位、认证,一个也不能少,如有需要,添加 微信:xnc528 备注:3
如若转载,请注明出处:https://www.clzz8.com/49213.html
相关推荐
-
一个男人对一个女人动心的表现,一个女人对男人动了情?
都说“女人心海底针”,可比女人心更为神秘、捉摸不透的是男人的嘴。 男人的嘴,不可信,这道理大家都懂! 可女性天生为感性动物,有时候就因为一个场景,一则故事,甚至是一个动作,触动了内…
-
建议大家不管灶台有多大,这3样东西尽量别放
厨房是我们家里面经常用的区域,若是不注意细节上的设计,肯定用着不方便。 相信很多人都会养成类似的习惯,厨房的灶台上堆满了各种各样的东西,只要是有地方就绝对不会控制,殊不知,这种做法…
-
紧随其后!中国版ChatGPT来了,国内第一个对话式型语言模型诞生
中国版ChatGPT终于来了,而且还不止一个。 这段时间,ChatGPT的风头正劲,很多人都在想,我们中国什么时候可以拥有一个ChatGPT呢?其实,在人工智能领域位列领先的百度表…
-
基于ChatGPT的视频摘要应用开发
随着在 YouTube 上提交的大量新视频,很容易感到挑战并努力跟上我想看的一切。 我可以与我每天将视频添加到“稍后观看”列表中的经历联系起来,只是为了让列表变得越来越长,实际上并…
-
才问了几个问题,美帝的chatGTP就叫我入会员,298元是交与不交?
才问了几个问题,美帝的chatGTP就叫我入会员,298元是交与不交? 回忆一下,才问了三个问题吧!就要我入会员了! 可恶的美帝啊! 网友们说说,我还有“如何评价吴友平8的头条文章…
-
巨爽的爽文推荐,
我刚下手术台,手机上传来我妈的消息。 “婷婷,告诉你一个好消息,妈怀孕了,你要有弟弟了。” 好消息? 我妈今年都55了。 孩子生下来,是她养,还是我养。 为了生儿子真是不要命了。 …
-
心阳虚冷汗_脾阳虚湿多_肾阳虚腿凉_4个中成药_温阳补虚,散寒补气
心阳虚冷汗多,脾阳虚湿气重,肾阳虚腿发凉,全身阳虚易生病。 大家好,我是刘医生。 很多朋友都知道阳气对我们身体的重要性,知道它可以温煦我们的身体,促进身体的生理功能,让我们保持健康…
-
兔年初八话“人与人”关系人与人相处的学问,人与人之间的关系有哪些称呼
祝朋友在新的一年好运连连、财源滚滚!每天都有好心情! 世界上最极致的东西是“人心”、“人心”最大的秘密是人性,人一生接触最多的就是人,千种万种人、千奇百怪人、千面万脸人,人与人相处…
-
四个字形容我爱你的意思是什么(四个字形容我爱你的意思是)
01/1- 我想到空旷的海上只要说爱你 鱼群就会跟着我游向陆地 1顾城《分别的海》 02/1- 亲吻睡觉旅行 抱在一起谈论爱情 下雨写诗想你. 等风住了等天晴 /宋小君《夏天最美好…
-
怎么样才能自救,如何自救_?
说到自杀方法,大家多是从影视剧上学来的,什么割腕自杀、咬舌自尽、喝农药、吞安眠药…… 其中,吞安眠药被贴上了温柔、无痛苦的标签,误认为是在昏睡状态下死去,类似于“安乐死”。这种错误…
