
相信很多人都已经在使用类ChatGPT的工具进行工作或者娱乐了,这里说的类ChatGPT的是指和ChatGPT相同或者相似功能的产品,包括国外的开源平替模型、百度的文心一言等,但是你真的会使用这些工具和应用吗?你使用的方法是正确的吗?
自人工智能大规模发展以来,ChatGPT这东西是第二个走进普通人眼中的应用,上一个走进普通人眼中的人工智能应用还是Alpha GO,但是Alpha GO是下围棋的应用,对于普通人而言只会感叹到它的智慧程度,除此再无其他感受。但是ChatGPT不一样,它是实实在在能提高生产力的东西,也是普通人能够使用的工具,它写论文、写方案、写小说、写总结、写代码、修BUG、做算术、搞翻译、做试题,在语言领域几乎无所不能。

对于一般人来说,只要你将ChatGPT这类工具使用的好,它就能为你带来意想不到的收获。如果你是老板,在企业生产中使用了ChatGPT,就可以缩减人员编制了,ChatGPT完全可以替代掉部分员工;如果你是员工,在日常工作中使用了ChatGPT,那么你的工作效率将会成倍的提升,在这个卷天卷地卷空气的社会,你就能快人一步胜出。
接下来我们将从ChatGPT的技术原理、任务需求、应用场景等方面来简要分析一下,如何对ChatGPT发起正确的沟通,如何引导ChatGPT输出我们想要的答案。
先上案例,比如我们让ChatGPT生成一个模仿影视剧中某个角色的说话方式来写一段发言内容:
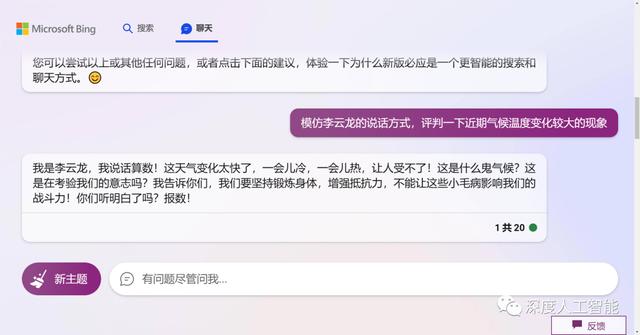
看了这个生成的结果,明显感觉差点意思,然后我们再继续调教,给它增加一些限制词,提示一下让它对自己的任务更加清楚一些,免得它乱发挥
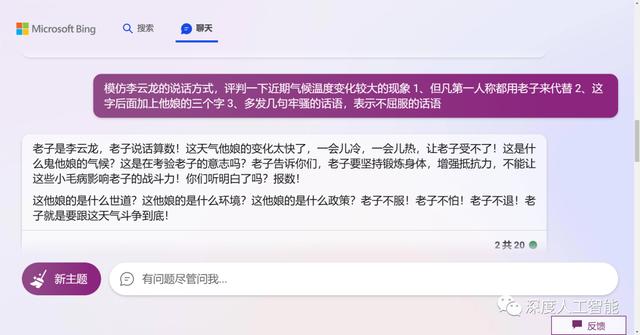
明显这次的生成结果比上次生成的结果要好上很多了,如果觉得还是不满意,可以继续修改或者增加限制词句提示。由于接下来的提示语句比较敏感,本人尝试了OpenAI的ChatGPT原版,竟然不给生成,可能是会涉及到“日本鬼子”这几个字吧,后来使用了微软的bing接口,也被拒绝生成,试了好几次,有一次终于凭着一流的手速截图留了证据,抱着试试看的心态,结果还好,勉强生成了一些内容。
这是被拒绝的:

这是凭着手速截的图:


上面的内容有些看不清楚,我分别裁开给大家看一下,感觉基本符合题目的提示要求:
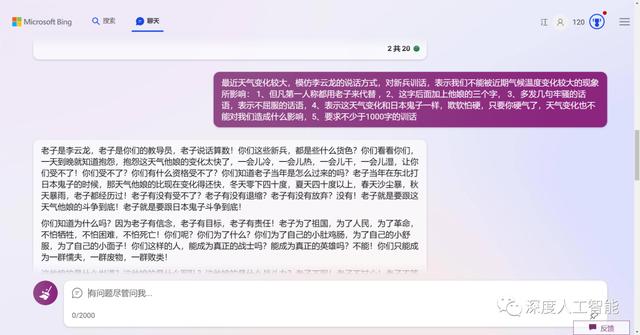

到现在为止,我们发现了一个规律,那就是ChatGPT生成的内容完全是可以按照我们的想法去生成的,但是你需要把这些想法告诉给它,否则只给它一个题目,他就会无边无际的说一些空话,因为它也不知道你的具体想法是啥,这就和考试写作文一样,如果只给你一个题目,不限分类体裁字数等,很可能有学生会写一首诗歌提交上去。
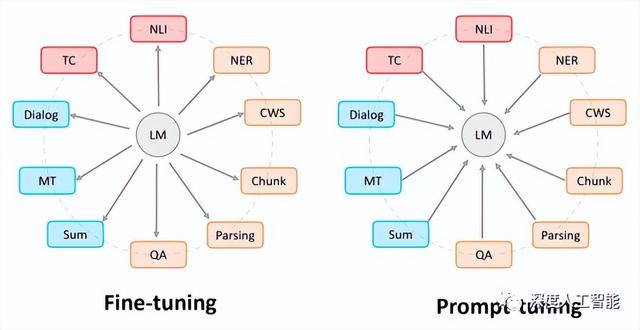
那么接下来我们思考一下,为什么ChatGPT需要被不断的提示,才会逐渐接近我们想要的答案,这就要说到接下来的一个名词了,那就是“Prompt Learning”或者“Prompt Tuning”,翻译过来就是提示学习和提示微调,在GPT3时代的时候,OpenAI就已经开始使用“Prompt Tuning”的方法来替代“Pre Training + Fine Tuning”的方法了,这里简述一下,“Pre Training + Fine Tuning”是一种使用预训练好的模型进行微调来完成任务的学习方法,这种方法在今年以前,基本一直都是大部分研究者和企业使用的主流技术方向,但是随着大模型越来越大,Fine Tuning变的越来越难的时候,就需要Prompt Tuning方法来解决问题了,OpenAI也是最早意识到这个问题的,从GPT3就已经使用了Prompt Tuning方法,现在的ChatGPT更是将Prompt Tuning方法推向了一个新高度。
Prompt Tuning热度的上升也意味着新主流研究方向也逐渐确定了,大概率可能就是Prompt Tuning了,国内外甚至因此出现了Prompt工程师。其实从EMLO 、Transformer、BERT、一直到GPT3之前的时代,大模型的训练学习基本都是以Pre training + Fine tuning 的形式实现,很多NLP基本都是以此为基准,应用到各种各样的任务之中。
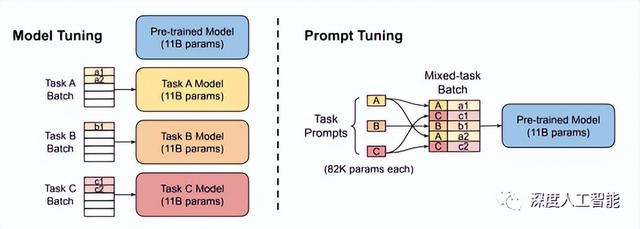
一般来说,Pre training阶段预会先训练一个Pre trained Language Model(PLM) ,然后在Fine tuning阶段根据PLM在具体任务中再次进行Fine tuning。当然这样做是有代价的,那就是Fine tuning阶段模型会引入新的Parameter,这会导致最终的结果与我们期望差异较大,而且在样本数量不变的前提下,单纯增加参数最大的问题就是会使得模型Overfitting,很大程度上降低了模型的泛化性能。再退一步来说就算没有上面的问题,随着Language Models越来越大,通过改变PLM原域Weight的Fine tune,其成本也越来越高,变革已迫在眉睫。
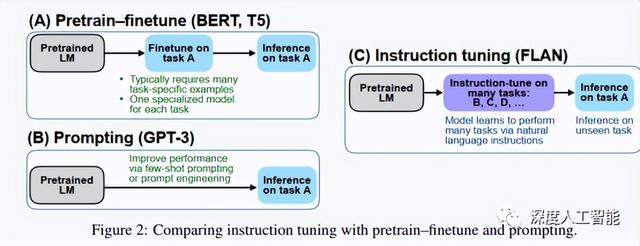
在GPT 3时代提出的一种基于预训练语言模型的新方法——Prompt Tuning 可能就是为解决上述问题,它主要是通过添加模板的方法来避免引入额外的参数,从而让语言模型可以在小Few shot或Zero shot的情况下也能达到我们想要的结果。个人认为其中最主要的一点就是Prompt根本不对预训练模型进行任何改动,是直接拿过来用的。它只改变输入到预训练模型里面的Prompt,通过改变这个Prompt来把域从原域(广域)切换到任务域上。
当然想要好的结果,使用Hard Prompt(Discrete Prompt)肯定不行的,可能效果还不如Pre training + Fine tuning,具体不展开了,简单说一下Soft Prompt(Continuous Prompt),Soft Prompt是把Prompt本身作为一个任务进行学习,相当于把Prompt的生成从人类prompt(离散)变换成模型自己进行学习和prompt(连续)。
如果让模型自己学习prompt,那就又回到了Pre training的问题,也就是会产生新的参数。看来引入新参数是不可避免的,为了保证学习的有效性,就需要一些soft Prompt的方法来验证,其中一种简单粗暴的方法就是把prompt变成token(当然也有其他各种混合使用的方法),这个时候的token就是prompt,它对于每个任务都是不同的,所以它可以帮助模型识别其任务到底是什么。又因为模型自己学习和tune这个prompt token,所以这个token对于模型会有非常好的效果。
总结一下来说,Pre training + Fine tuning是调整语言模型的参数,让语言模型的参数去匹配任务,当任务越来越难,模型就会越来越大,因此对整个模型的原域参数进行Fine tuning的成本也就会越来越高;而Prompt Tuning是调整任务格式,让任务格式去匹配语言模型,这对超大的PLM参数来说,完全没有任何改变(减轻了很多压力,可以搞更大的PLM了),只是增加了一些Learnable prompt token而已,当然前提是预训练模型必须足够好。所以会使用提示性、精准限制性的方法向ChatGPT提问,你才会得到更惊喜的答案,否则,开放式的提问,你只会感觉它还不如你家孩子。
如果想让ChatGPT能更好的一次性输出人类想要的内容,就需要它自己模拟人类不断的给自己提示,然后输出内容。巧的是国外的研究团队已经替你想到了,他们基于ChatGPT改进了一种新的模型,叫做Auto GPT,听名字就知道它是一个自动GPT问答模型,实际上就是自问自答,模仿人类的问答方式不断迭代升级,有点像Alpha Zero(Alpha GO的最终版)的双手左右互搏的学习方法,在学习过程中有不懂的地方还会上网搜索学习,当然,现阶段的自问自答还是以人类的对话为基准而训练的,使用的RLHF(人类反馈强化学习方法)。可以想象一下,如果去除了人类的干预,让模型自己学习下去,毫无疑问,可能会出现另一种逻辑方式,可能是人类理解不了,但是模型之间可以理解的自然语言。

关于如何调教ChatGPT模型,以及它为什么需要被调教的内容就到此为止。后续有其他方向的技术技术更新,我们也会及时跟进与大家分享。希望国内的大语言模型在用户体验上也能逐渐向ChatGPT靠近,当然理性一点来说这种情况还需要一段时间,人工智能技术的发展和芯片技术没有太大区别,最终都是需要人才的,而国内的人工智能人才缺口超过了500多万,据工信部发布的AI人才报告显示,相关岗位的供需比甚至低于10%,这是什么概念?相当于行业需要100个人AI人才,而市场能够提供的合格人才不足10个,当然这个问题不是短期内能弥补上的,毕竟我们老话常谈,十年树人百年树木。
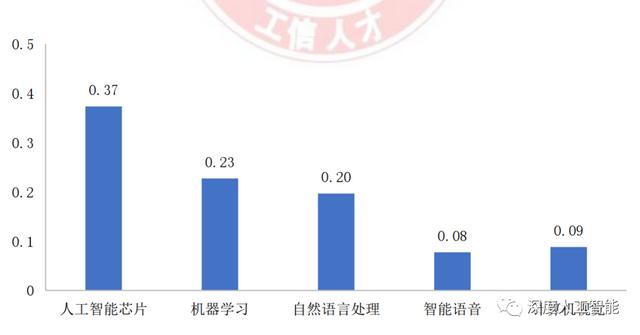
目前全世界500多家AI企业中,美国占到了300多家,而中国只有30多家;在硬件方面,全球90%的人工智能芯片都来自于美国,第一名的英伟达公司只发展了30年,总部同样在美国。然而,即使中美AI在硬件和研发能力上存在这么大的差距,谷歌公司的前总裁,现任美国国防部创新咨询委员会主席的埃里克·施密特仍然认为,美国需要加大AI技术研发,以应对中国日益激烈的竞争。
ChatGPT出现之前,中国的AI发展好像已经是世界第二了,大约还能看到第一名的尾巴。但是ChatGPT的出现,把我们带回了现实,中美之间的差距仍然很大。可以说,从GPT3开始,中美之间的AI技术差距就已经开始拉大了,只是在ChatGPT出来后,很多人觉察到了这一点而已。之前美国人研发的产品,比如以Diffusion Model为核心的AI绘图,再比如初代的谷歌聊天机器人,那都是开放源代码的,这让国内的高校和企业很快跟着做出来了类似产品。
但是从GPT3、DALL-E、Codex 开始,一直到现在的ChatGPT、GPT4等模型都没有开放源代码,国内自己动手做的时候就有难度了。至于国内的类ChatGPT模型,实际上的体验大家都有感悟,这里就不含开讨论了。那么难点到底在哪里呢?有人说是芯片,中国的芯片技术被外国卡脖子了,是不是在这一方面限制了AI的发展呢?其实关键不在于制造芯片的难度,不在于原材料的问题,而在于核心的AI算法,本质上比拼的是科研人员的研发能力和国家的基础学科建设,以及人工智能人才梯队的建设。而算法人才的稀缺导致了该岗位是目前人工智能行业薪资最高的岗位,去年ChatGPT还没有出来之前,脉脉人才智库发布的人工智能人才岗位薪资就显示人工智能算法工程师的平均起薪达到了32208。

在人工智能人才建设方面,国家也早已经意识到了不足之处,为了培养国内的人工智能人才,国家也陆续出台了很多相关政策来支持,包括大学专业、人工智能技能培训、甚至浙江今年开始从小学开始就把人工智能课程作为了必修课程。此外,国家也出台了相关的人工智能证书来引导行业的良性发展,其中工信部教考中心颁发的《人工智能算法工程师》职业能力证书是目前行业中报考人数较多的证书,证书分为初级、中级、高级三个级别。根据国家发布的新规,目前人工智能行业的证书都是培训+考证的方式,这也是为了杜绝以往的持证不上岗,上岗不持证的问题。该证书课程含金量高,国内很多国企单位机构以及学校老师都在报考该证书。对于想学习人工智能进入人工智能行业的人员来说,这不失为一个两全其美的方法,既学习了课程,掌握了知识技能,还获得了职业能力证书。

最后也希望国内的人工智能人才建设能够日趋完善,为国产人工智能的发展增砖添瓦。随着中美政治、经济、科研等多方面的不断脱钩,国内人工智能行业对人才的需求也会越来越大,相关的薪资待遇也会水涨船高,将会是新一轮持续时间较长的风口行业。
生意营销3大宝:彩铃、定位、认证,一个也不能少,如有需要,添加 微信:xnc528 备注:3
如若转载,请注明出处:https://www.clzz8.com/48199.html
相关推荐
-
不读书,小心会被ChatGPT们取代哦
你有多久没读书了? 一年一度的世界读书日到了,这个问题就像一句“灵魂拷问”,在今天这个特殊的日子里,成为大家共同讨论的问题之一。 1995年,联合国教科文组织设立“世界读书日”,其…
-
耳洞臭臭的怎么办
不论男女,耳饰都是一种流行的时尚配饰。尽管打耳洞的风险比其他身体穿孔的风险要小,但也有可能引起并发症。为了避免感染,一定要知道如何清洗新打的耳洞,以及在耳洞愈合后该如何保养耳洞,这…
-
想被你“耕耘”的女人,会给你这四个“暗号”,别错过了?女人想让你耕地的暗示女人哪四!
女人天生就是比较感性的生物,她们对于一切自己感兴趣的事情,都会不由自主的产生一些好感,如果她对你发出这四个暗示,说明她想要了,至于要什么,你懂! 1、她想和你一起看电影,而且是恐怖…
-
ChatGPT应用技巧四复杂文本的分析及处理
随着AI时代的到来,很多以前复杂的数据处理工作可以利用AI来完成。这其中大语言模型尤其擅长的是对语言类文本的处理,今天就来聊聊如何利用ChatGPT+提示工程,来处理、分析和提取复…
-
高颜值国风黄色系美女写真组图推荐Vol.23.031,黄色女人
本图文由笨小狗狗原创发布 回眸一笑百媚生, 六宫粉黛无颜色。 她的容颜,如花绽放, 她的风采,如日升之光。 她的微笑,如春风拂面, 她的眼神,如秋水清澈。 她的存在,让人心潮澎湃,…
-
日本人的睡眠最少,但为何寿命最长?,中国最长寿的10个人
#头条创作挑战赛# 2020年的时候,世界著名的医疗设备制造商飞利浦在全世界13个国家,针对1万3000人做了一次“世界睡眠调查”,结果显示,睡眠满意度比较高的国家,一是印度(76…
-
被男生公认不好看的4种“发型”,颜值高也很难拯救,你中过没
发型的修饰呈现简直可以说可以改变整个人的气质,别看它面积不大且选择性很多,但是如果所选择的发型并没有任何修饰的能力,会直接拉低自身的魅力值和气质。 尤其是有几款被男生公认的最不好看…
-
台湾什么时候能回到祖国怀抱
叶耀鹏,台湾时事评论员,原民进党创党元老,如今是两岸统一的坚定支持者。他在今日头条有自媒体头条号《叶耀鹏台湾》,粉丝量达到211.3万。 最近看到他的一条视频,标题是《为何两岸统一…
-
这几个星座在职场中出类拔萃,是当之无愧的王者
职场中根据岗位需要具备的才能不同,可以说是五花八门,各有千秋,可是有几个星座做啥像啥,出类拔萃,可以成为那个领域的王者。 狮子座 狮子座是领导和管理能力出众、充满自信和热情的代表。…
-
为何年轻人胃部不适去看病时,医生不建议做胃镜?帮你揭晓答案
导语:时代变了,最困难的时期早已过去,材料短缺的阴霾已逐渐消失,经济水平不断提高,各种各样的食物,包括大鱼和肉,都逐渐摆上餐桌,然而,在繁荣的背后,患有肠胃疾病的人群也逐渐增多。 …
