
ChatGPT让我们见识了大模型技术的强大潜能,激发了市场的热情。
然而,对于大多数人而言,最关心的问题很可能是——如何用ChatGPT赚钱。谈到赚钱,最直接的就是金融,其中最可能在短期内产生超额收益的当属股票投资。
这就衍生出一个关键的问题:可以用ChatGPT来预测股价么(也就是炒股)?
我们并不需要ChatGPT能够达到100%的准确度,只要他的表现能够超越大部分普通人,就能够在一定程度上实现“打败市场”的目标,实现超额收益。
接下来,本文将对这个问题进行严肃、系统的分析。本文将探讨大模型在股价预测领域的应用、技术原理、优势与局限性,以及与其他AI模型融合的实例分析。同时,讨论大模型对资本市场的影响、监管挑战和未来发展前景。
以前预测股价的AI工具表现拉胯
我们知道,预测股票价格波动本质上是一项具有挑战性的任务,因为市场受到许多不确定因素和内在机制的影响。在进行股价预测时候,投资者往往关注以下四个方面:
技术分析:这种方法主要关注价格和交易量等历史数据。投资者可以研究图表模式、趋势线和技术指标(如移动平均线、相对强度指数(RSI)和布林带等)来分析市场动态。
基本面分析:这种方法侧重于研究影响股票价格的宏观经济和微观经济因素,如公司盈利、行业趋势、国内生产总值(GDP)和失业率等。基本面分析有助于确定股票的内在价值和潜在增长。
新闻和事件:关注与公司和行业相关的新闻事件,如盈利报告、新产品发布、管理层变动等,这些事件可能对股票价格产生重大影响。
市场情绪:投资者的情绪和市场心理也是影响股票价格波动的关键因素。恐慌、贪婪和其他心理因素可能导致股票价格偏离其基本面价值。

用AI来预测股价并不是一个新鲜事,事实上已经有大量AI模型被用来进行股票预测,以下是几种比较常见的AI模型:
线性回归(Linear Regression):
线性回归试图通过拟合一个线性方程来描述输入特征与目标变量(股价)之间的关系。线性回归假设特征和目标之间存在线性关系。对于具有线性关系的数据,线性回归可能表现良好。然而,股票价格往往呈现非线性特征,因此线性回归可能无法捕捉复杂的市场动态。
支持向量机(Support Vector Machine, SVM):
支持向量机是一种用于分类和回归的监督学习模型。在股价预测中,SVM通过最大化特征空间中正负样本间的间隔来拟合一个超平面,从而预测未来的股价。SVM可以捕捉非线性关系,并具有较好的泛化能力。然而,参数调优和计算复杂度较高,可能影响预测效率。
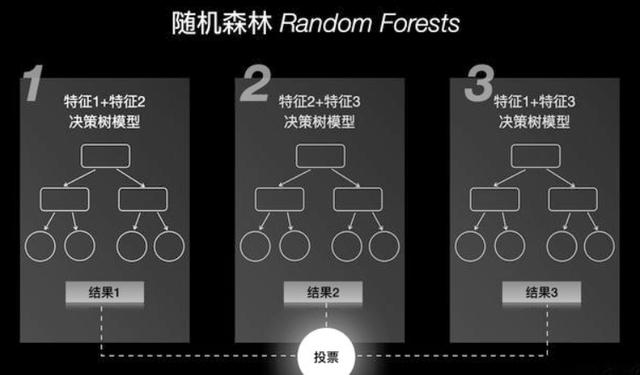
随机森林(Random Forest):
随机森林是一种集成学习方法,它通过构建多个决策树并将它们的预测结果进行平均或投票,从而提高预测准确性和稳定性。随机森林可以很好地处理非线性关系,抗过拟合能力较强。然而,其可解释性较差,且在某些情况下可能无法充分捕捉时间序列数据的依赖性。
梯度提升树(Gradient Boosting Machine, GBM):
梯度提升树是一种集成学习方法,通过迭代地训练一系列弱学习器(通常为决策树),并将它们的预测结果进行加权累加,从而提高预测性能。梯度提升树具有较强的预测能力和较好的抗过拟合性,但训练过程可能较慢,且可解释性相对较差。
长短时记忆网络(Long Short-Term Memory, LSTM):
LSTM是一种循环神经网络(RNN)的变体,能够捕捉时间序列数据的长期依赖关系。LSTM通过引入“门”结构来解决RNN的梯度消失和梯度爆炸问题。LSTM在处理具有长期依赖关系的时间序列数据方面表现优秀,因此对于股票价格预测这类问题具有较高的潜力。然而,LSTM需要大量的计算资源和训练时间,且调参过程较为复杂。
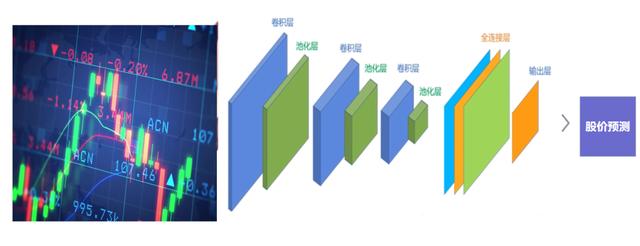
卷积神经网络(Convolutional Neural Networks, CNN):
CNN是一种深度学习模型,主要用于处理具有局部相关性的数据,如图像。在股票价格预测中,可以将多个时间窗口的价格数据视为二维数据(时间×特征),并利用CNN捕捉局部模式和关系。CNN在捕捉局部特征方面表现优秀,可以用于处理非线性和复杂的股价数据。然而,与其他深度学习模型一样,CNN需要大量的计算资源和训练时间,并且容易过拟合。
上面的AI模型各有特点,但都有一个共同的缺陷,就是模型的参数规模较小,无法表征更复杂的市场关系。而一个股票的价格变动是由很多因素综合决定的,其中有非常复杂、非线性的关系,简单的模型往往无法模拟更无法预测这种复杂性。
因此,人们苦苦寻找更强大的AI模型。
大模型闪亮登场,为炒股而生?
随着大模型技术的发展,人们开始将注意力放在大模型身上。
大模型通常采用Transformer架构,以自注意力(Self-Attention)机制为核心。通过对输入序列中的每个元素进行自注意力计算,大模型可以捕捉长距离依赖关系,从而在时间序列分析任务中表现出色。此外,大模型采用预训练-微调(Pretrain-Finetune)的训练策略,在大规模无标签数据上进行预训练,然后在具体任务的有标签数据上进行微调。这使得大模型能够充分利用海量数据进行学习,获得强大的表示学习能力。
在股价预测领域,大模型可以处理大量异构数据,如股票交易数据、宏观经济数据、公司财务报告等,同时还可以处理非结构化数据,如新闻报道、社交媒体信息等。这使得大模型能够从多方面捕捉市场信息,提高预测准确性。
与传统模型相比,大规模预训练模型有多方面的优势,主要表现在:
自动特征学习:传统模型通常需要手动设计和选择特征,这可能需要大量的领域知识和经验。而大型模型可以在训练过程中自动学习和提取有用的特征。这使得它们能够更好地捕捉到隐藏在数据中的复杂模式和关系。
处理多种数据类型:大型模型可以处理多种类型的数据,如文本、图像、时间序列等。这使得它们能够更好地整合股票价格预测所需的各种信息,如新闻、社交媒体、财报等。
强大的表示能力:大型模型具有更多的参数和更深的网络结构,使得它们具有强大的表示能力。这意味着它们可以捕捉到更加复杂和高阶的数据特征,从而提高预测的准确性。
预训练和微调策略:大型模型通常采用预训练和微调的策略。在预训练阶段,模型学习到通用的知识和特征;在微调阶段,模型使用特定于股票价格预测任务的标注数据进行训练。这种策略可以提高模型的泛化能力,使其能够更好地应对不同的股票市场和交易环境。
端到端训练:大型模型通常采用端到端的训练方式,即直接从输入数据到预测结果的映射。这种训练方式可以避免中间步骤的误差累积,从而提高预测的准确性。
正是因为大模型有这些特点,其天然比较适合用于预测股价。
大模型并不是完美的,还需要融合其他模型
需要注意的是,尽管大型模型在股价预测方面具有一定的优势,但股票市场的复杂性和不确定性使得预测仍然具有挑战性。并且,如果单独用大模型,也会存在一些明显的短板。比如,尽管ChatGPT在处理文本序列方面表现出色,但它可能不如专门针对时间序列建模的模型(如LSTM、GRU等)有效;股价预测通常需要综合多种类型的数据,如股价历史、技术指标、宏观经济数据等。ChatGPT主要处理文本数据,可能无法直接处理这些非文本数据。
因此,在实际应用中,建议将大型模型与其他模型相结合,或者采用集成学习方法,以提高预测的准确性和稳定性。
接下来,我们就来深入探讨一下要更准确的预测股价波动,应该怎样改造大模型。
为了打造一个在股价预测方面更强大的综合模型,可以考虑将ChatGPT与以下类型的模型结合:
时间序列模型:如长短时记忆网络(LSTM)或门控循环单元(GRU)等循环神经网络(RNN)模型,这些模型在处理时间序列数据方面具有较强的能力。结合这些模型可以更好地捕捉股价历史数据中的时间依赖关系。
强化学习模型:如Q-learning、深度Q网络(DQN)或Actor-Critic等,这些模型可以从交互中学习并优化决策。将强化学习模型与ChatGPT结合,可以更好地根据市场环境进行动态决策。
集成学习模型:如随机森林、梯度提升树(GBM)或XGBoost等,这些模型可以对不同来源的数据进行融合和优化。将集成学习模型与ChatGPT结合,可以充分利用各种类型的金融数据。
那么,怎么将上述模型与大模型进行融合呢?一般而言,并行结合、级联结合、混合结合是三种比较常见的模型融合方法。
并行结合:在这种方法中,不同模型分别处理相应的数据类型,然后将各模型的输出整合到一个融合层,共同进行股价预测。例如,ChatGPT处理新闻和社交媒体数据,LSTM处理历史股价数据,强化学习模型处理市场动态。将各模型的输出输入到一个神经网络或者集成学习模型中,得出最终预测结果。
级联结合:在这种方法中,不同模型按顺序进行处理。例如,首先使用ChatGPT从新闻和社交媒体数据中提取市场情绪特征,然后将这些特征与股价历史数据一起输入到LSTM模型中进行时间序列建模。最后,将LSTM的输出输入到强化学习模型中进行动态决策。
混合结合:将不同模型的某些层次混合在一起。例如,在一个深度学习模型中,可以将ChatGPT的某些层与LSTM或GRU的层结合起来,共同进行特征提取和预测。这需要对原始模型进行修改,以实现更紧密的集成。
要成功打造一个强大的股价预测综合模型,需要充分考虑各个模型的优势,合理选择结合方法。同时,关注数据处理、特征工程、模型训练和调整等关键环节,确保模型能够适应市场变化。
“纯手工”打造一个能预测股价的大模型
上面,我们从原理上分析了大模型用于股价预测的可能性,并分析了如何改造大模型让其有更好的股价预测表现。那么,具体该怎么从头到尾打造一个这样的大模型呢?接下来,我们以尽可能精简的步骤来打造一个这样的大模型。
首先,是需要构建一个专门的训练数据集,数据集的质量的规模在很大程度上影响着模型的表现。
要构建一个在预测股价方面尽可能强大的大模型,需要收集多种类型的数据,比如历史股价和成交量数据、市场指数和宏观经济数据(如GDP、通货膨胀、失业率等)、公司财务报告(如季度报告、年度报告)、新闻报道和分析师评级、社交媒体和在线论坛数据(反映市场情绪)、技术指标(如移动平均线、相对强弱指数等)、行业和公司特定信息(如行业趋势、竞争对手情况、公司治理等)。
要获取这些数据,可以从雅虎财经、Google Finance、Quandl、FRED(Federal Reserve Economic Data)等公开金融数据源,Bloomberg、Refinitiv、FactSet等付费金融数据提供商,通过网络爬虫、API或第三方服务收集新闻文章、推文等,从公司官方网站收集公司财务报告、新闻稿等渠道获取。
此外,许多金融数据提供商(如Bloomberg、Refinitiv等)提供实时数据服务。这些服务可能提供API,以便将实时数据直接输入到模型中。可以使用消息队列和数据流处理技术(如Kafka、Apache Flink等)来实时获取和处理数据,这有助于在模型中实时更新和处理新数据。
获得数据之后,还要对数据进行预处理。主要包括:数据清洗,去除无关信息、缺失值、异常值等。格式转换,将非结构化数据(如新闻、社交媒体)转换为模型可处理的格式,例如使用自然语言处理技术提取关键信息。归一化,将数据缩放到相同范围,以便模型更好地捕捉特征间的关系。特征工程,从原始数据中提取有用的特征,例如计算技术指标、市场情绪等。
接下来的一项重要工作,就是构建模型。这个过程中,一个关键环节是多模型的融合。上面我们已经介绍了多种将ChatGPT这类大模型与其他AI模型融合的方法,可以借鉴。
完成数据集的构建和模型构建工作之后,就可以开始进入模型训练调优阶段了,这又分为预训练和微调两个阶段。
预训练阶段:模型在大量的非结构化数据(如文本、图像等)上进行预训练,学习到通用的知识和特征。这些特征包括语法、语义、背景知识等,可以帮助模型更好地理解股票市场的背景和影响因素。
微调阶段:在预训练阶段的基础上,模型使用特定于股票价格预测任务的标注数据进行微调,这些数据可能包括股票价格、交易量、公司财报、市场情绪等多种类型的数据。通过微调,模型可以学习到与股价预测相关的特定知识和特征。
迟早会出现一个“猛人”,用ChatGPT来“打败市场”
在金融领域,“打败市场”是所有投资人的梦想。但凡有一点实现的可能,就必然会有大量的人前赴后继。
因此,如果ChatGPT这类大模型在股价预测方面巨大潜力,相信会有不少富豪、投资机构斥巨资来打造这样一个大模型。如果这样的工具真的出现了,会怎么样呢?
接下来,我们来畅想这样一个故事:
有一位名叫亚历山大的年轻富翁,他拥有着无尽的财富,但心中却有一个更为远大的梦想。亚历山大渴望利用先进的科技,打破传统的投资界限,打造一个能够准确预测股价的神奇系统。
亚历山大开始寻找世界各地的顶级人才,组建了一个由金融精英、数据科学家和计算机专家组成的团队。他们共同致力于开发一个以超万亿参数规模的大模型为基础的预测系统,试图利用先进的技术和海量的金融数据,揭示股市的奥秘。
为了达成这个宏伟的目标,亚历山大毫不犹豫地投入巨资购买专业金融数据,使这个预测系统能实时接入互联网,获得最新的宏观经济、市场动态、公司动态、财务数据以及整体市场情绪等信息。他相信,有了这些数据的支持,这个神奇的系统将能够对股票价格走势进行精准预测。
经过数年的努力,亚历山大和他的团队终于开发出了这个名为“神盾”的股价预测系统。在测试阶段,“神盾”表现出惊人的预测能力,使亚历山大信心满满。然而,他们也意识到,股市的复杂性和不确定性,使得这个系统仍然面临巨大的挑战。
在“神盾”投入实战后,亚历山大开始在市场中大展拳脚。虽然面临着诸多的竞争对手和市场波动,但“神盾”仍然能在很多时候帮助亚历山大取得令人瞩目的超额回报。然而,在某些情况下,这个神奇的系统也难以抵挡市场的不确定性和意外事件。
即使如此,亚历山大和他的团队并未放弃。他们不断地优化“神盾”,利用更先进的技术和方法,努力提高系统的预测准确率。最终,尽管“神盾”并不能保证始终打败市场,亚历山大的努力却为整个金融科技领域带来了革命性的突破亚历山大的“神盾”预测系统开始引起世界各地金融界的关注。许多投资者和金融机构纷纷前来寻求与亚历山大合作的机会,希望借助“神盾”的力量来提高他们的投资回报。
亚历山大决定创立一家金融科技公司,将“神盾”预测系统提供给广大投资者和金融机构使用。公司迅速扩张,成为世界上最顶尖的金融科技企业之一。
随着“神盾”越来越受到人们的关注,亚历山大和他的团队也开始面临新的挑战。一些人开始质疑“神盾”预测系统对市场稳定性的影响。为了解决这些问题,亚历山大决定投入更多资源进行研究,以确保“神盾”在为投资者创造价值的同时,不会对金融市场产生不良影响。
经过不懈的努力,亚历山大和他的团队成功地研发出了新一代的“神盾”,这个升级版的系统在预测股价的同时,还能评估市场的风险和稳定性,从而确保金融市场的健康发展。这一突破性的创新再次引起了世界各地的关注。
在亚历山大的领导下,“神盾”逐渐成为了金融科技领域的一面旗帜。他的努力改变了传统投资领域的格局,推动了金融科技的发展。尽管“神盾”并不能保证始终打败市场,但其带来的收益已经足以让亚历山大成为世界首富了。
ChatGPT会是新的割韭菜利器么?
在上面畅想的故事中,我们主要关注到ChatGPT在金融领域有利的一面。然而,越是强大的科技,就越危险。
由于这些投资机构利用先进的技术持续超越市场,市场上的定价效率可能会提高,因为更多的信息会被迅速地整合到股票价格中。然而,这也可能导致市场波动性增加,因为大量机构纷纷寻求利用技术优势实现快速交易。
对于使用大模型的投资机构而言,他们可能在很大程度上降低了投资风险并提高了收益。但对于没有使用这些技术的散户和其他投资者来说,他们可能会面临更高的风险,因为他们无法及时获取和处理与大模型相匹敌的信息。这可能导致市场的收益不均衡,使得更多的收益集中在使用大模型的投资者手中。对于没有使用这些先进技术的散户和其他投资者来说,这确实可能会产生不公平的竞争环境。这些投资者可能无法在信息和技术上与使用大模型的机构抗衡,从而导致他们在市场上处于劣势地位。

对于监管层而言,如何确保市场公平、透明和稳定将成为一个巨大的挑战。监管者可能需要加强对这些大模型的监管,以防止市场操纵、内幕交易等不正当行为。此外,监管层还需要评估这些技术对市场稳定性的影响,并采取相应的措施以确保金融系统的安全。
总之,大模型在股价预测领域具有巨大的潜力,但要充分发挥其优势并确保市场的稳定和公平,我们需要不断地进行技术创新和监管调整。投资者、企业和监管机构都需要密切合作,共同探索更高效、公平的市场机制。在未来,随着技术的进一步发展和市场的逐渐成熟,大模型或将成为股价预测领域的重要工具。
文:一蓑烟雨 / 数据猿
生意营销3大宝:彩铃、定位、认证,一个也不能少,如有需要,添加 微信:xnc528 备注:3
如若转载,请注明出处:https://www.clzz8.com/46963.html
相关推荐
-
订制彩铃广告语,订制彩铃广告语怎么写?
订制彩铃广告语,订制彩铃广告语怎么写? 订制彩铃广告语是种吸引用户注意力的重要手段,通过精心设计的广告语可以吸引更多用户订制彩铃,提高彩铃服务的销售量下面是一些编写订制彩铃广告语的…
-
家里很多小蚂蚁找不到源头4楼(家里很多小蚂蚁找不到源头知乎)
蚂蚁种类繁多,在中国就有600多种,其中以红火蚁、白蚁危害最为严重,蚂蚁在地球上分布极为广泛,几乎是无孔不入,庭院养花种菜、阳台、楼顶的花盆里都会有蚂蚁出没,烦不胜烦,如果盆土里有…
-
形容女孩子有气质有涵养的古诗词形容女孩子有气质有涵养的古诗词带解释!
(一) 暗送秋波 :本指女子暗中以眉目传情,引申为献媚取宠,暗中勾结。秋波,比喻美女的眼睛。语本宋苏轼《百步洪》诗之二:“佳人未肯回秋波,幼舆欲语防飞梭。” 霞裙月影 :以云霞为裙…
-
最吉利的十种梦梦见拉屎十大吉利梦梦见自己拉屎!
日有所思, 夜有所梦。关键是还能解梦,自己解梦。昨天睡得不好,一直在做梦。记得三个梦。 梦里的我想出名,与一个知名的相声演员认识了,他说:"你要出名可以,我帮你。网友有一条写我的评…
-
老中医家里的4棵树,好养不说,还很“养人”,树旺人更旺
哪怕已经过了二三十年,有的时候,有些小时候发生的事情,依然还历历在目。 只是现在已经是沧海桑田,除了一年一次的陪伴老人回家一趟之外,已经看不到小时候的样子。 比如我老家的二祖父家,…
-
面对ChatGPT双刃剑,如何趋利避害?
ChatGPT绝对是近期媒体报道热点中的热点。生命未来研究所(Future of Life Institute)日前在他们的网站上贴出了一封“公开信”,一石激起千层浪。 “公开信”…
-
逆向思维你想要做自媒体赚钱,就是三种最简单的方式,手机上怎么赚钱啊_正规
逆向思维:你想要做自媒体赚钱,就是三种最简单方式。 任何复杂的事情,都有简单的解决方法。 这就是阴阳平衡,物极必反的道理。 很多事情千万不要想的太复杂,之所以复杂,都是你“想象”的…
-
看看Nike、adidas、levis、ck等品牌三年时间的产地变化
三年前给孩子买衣服基本都是made in china,今天买了些,回家偶然发现,现在都是made in约旦、墨西哥、越南、斯里兰卡……, 慢慢的就被蚕食掉了……。
-
2023年监理工程师案例黄金考点建安工程费清单计价,总监必考点
2023年监理工程师案例黄金考点建安工程费清单计价,总监必考点,长按点赞+转发+评价持续更新哦,文荡版点我头像私信我:2022 (1)分部分项工程费= Σ(分部分项工程量×综合单价…
-
杭州十大旅游景点
第一: 杭州西湖 (5A) 杭州西湖因秀丽湖光山色和众多的名胜古迹闻名中外,是中国的著名的旅游胜地,也被誉为人间天堂。景区内群山高度不超过400米,环布在西湖的三面,其中吴山和宝石…
