
4月18日,阿卜杜拉国王科技大学的研究团队开源了类ChatGPT模型MiniGPT-4。除了生成文本之外,具备识别图片的多模态功能。这与微软前不久开源的Visual ChatGPT非常相似,也是一个“眼睛+嘴巴”的组合模型。
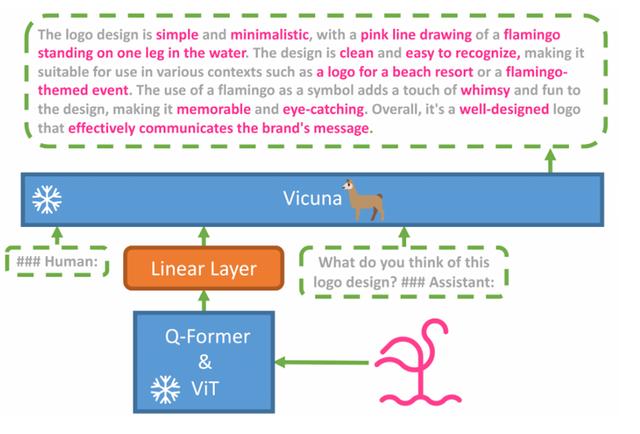
据悉,MiniGPT-4 由一个带有预训练 ViT 和 Q-Former 的视觉编码器、一个线性投影层以及高级 Vicuna 大型语言模型组成。其中,Vicuna是一个130亿参数的类ChatGPT开源模型,性能方面媲美GPT-4。资源消耗非常低,可以在单个 NVIDIA 3090/4080/V100(16GB) GPU 上运行。
ViT和Q-Former视觉编码器,可以根据图片和提示生成文本,这也充当了MiniGPT-4的“眼睛”,具备看图说话的功能。
开源地址:https://github.com/Vision-CAIR/MiniGPT-4
在线试用:https://687d119023cd37e5fb.gradio.live/
论文:https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
Open AI发布的GPT-4大语言模型再一次拉升了ChatGPT的能力,其强大的看图说话能力进一步扩大的ChatGPT的应用范围。由于GPT-4没有开源并且API需要申请审核才能使用,这让很多企业、开发者只能干羡慕。
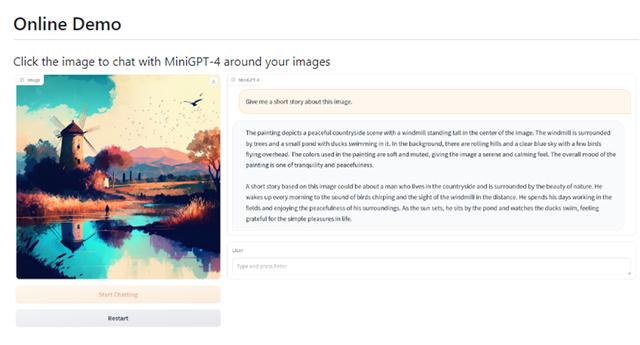
MiniGPT-4为了探索GPT-4功能,通过将类ChatGPT模型与视觉模型相结合使用,从而实现类似GPT-4的看图说话功能。例如,上传一张田园照片,然后问“能帮我讲一个关于这张照片的小故事吗?”。AI机器人很快就能为用户创作一段故事。
其实,MiniGPT-4这种组合方法并不新鲜,微软之前开源的Visual ChatGPT就采用过。他们将类ChatGPT模型与多个 SOTA 视觉基础模型连接,实现在对话系统中理解和生成图片。目前,该开源项目在github已突破3万颗星非常受欢迎(开源地址:https://github.com/microsoft/visual-chatgpt)
但想以最佳效果实现模型组合也并不容易,因为整个映射、对齐过程非常复杂、繁琐,例如,有大量重复、难以理解的语句和图片,微调效果不佳整个产品的性能也将大打折扣。
模型训练方面,MiniGPT-4一共采用了两个阶段进行训练。第一阶段预训练,该模型使用来自Laion和CC数据集的图像文本对进行训练,以对齐视觉和语言模型。训练完成后,视觉特征被映射,可以被语言模型理解。
第二阶段微调,使用独立创建的小型高质量图文对数据集,并将其转换为对话格式以进一步对齐MiniGPT-4。在对齐之后,MiniGPT-4 能够连贯地理解用户意图,并根据图片生成特定文本内容。总体而言,在两个阶段完美训练之后,MiniGPT-4达到了可以媲美GPT-4的能力。
功能方面,根据MiniGPT-4展示的示例来看,在识别图片方面非常优秀,可以根据用户的图片和提问自动生成相对应的文本内容。例如,根据一张鸟叼着灯的图片,让机器人生成一则广告。
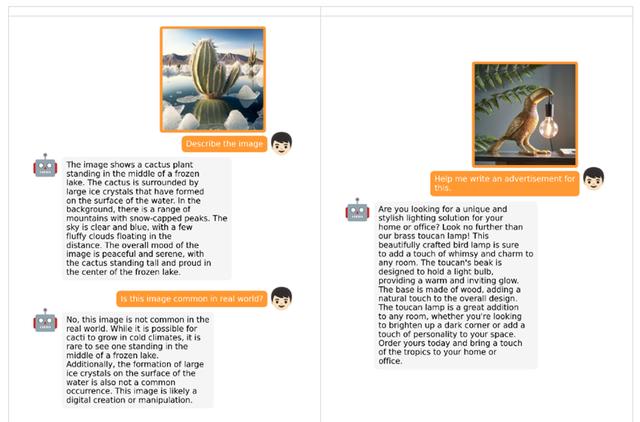
此外,MiniGPT-4支持多轮连续对话,可以根据特定图像为用户生成更有深度的内容。
值得一提的是,本次开发的MiniGPT-4是一个阿卜杜拉国王科技大学华人博士团队完成,包括,朱德尧、Chen Jun、沈晓倩、LiXiang和Mohamed Elhoseiny教授。


本文素材来源MiniGPT-4,如有侵权请联系删除
生意营销3大宝:彩铃、定位、认证,一个也不能少,如有需要,添加 微信:xnc528 备注:3
如若转载,请注明出处:https://www.clzz8.com/45945.html
相关推荐
-
为儿子学费 工人高温工作9小时去世
自7月初以来,许多地方的极端高温一直持续下去,甚至出现了热死人的情况。据媒体报道,浙江许多医院中暑患者已被送往医院,许多人被诊断为热射病,并有死亡病例,江苏和四川也被诊断出来。 7…
-
真香_好用到哭!3个黑科技神器_【ios安卓】,苹果必装3个黑科技软件下载
简讯 有些事知道结论就够了 所谓理想至少要见多识广。简讯·微杂志(tipsoon)涵盖全球范围内的旅行、电影、黑科技、音乐、电影、生活、娱乐等多方面的内容, 每篇杂志内容都很简短,…
-
星座的神秘力量了解十二星座
星座一直以来都是人们非常感兴趣的话题,它们代表着我们的性格特点和行为方式,也影响着我们的人际关系和生活。每个人的生日都与某个星座有关,下面让我们了解一下每个星座的特点和神秘力量。 …
-
足力健老人鞋送长辈合适吗,他们喜欢穿吗?(四)
每次想给父母长辈挑选礼物的时候都不知道选什么好,市面上专属老年人的产品并不少,到底哪些才是真正适合老年人的呢?其中在众多老年用品中,足力健老人鞋一直深受大家关注,也成为了很多年轻人…
-
五行应该怎么行气?天干十神才是五气运行的黄金标准,相生相克五行表
金木水火土,五行具有阴阳的属性。 天干阴阳五行 金分阴金和阳金、木分阴木和阳木、水分阴水和阳水、火分阴火和阳火、土分阴土和阳土。 阴阳五行配以天干,每一天干都具有唯一的属性,如甲为…
-
这四所“理工”大学,各有特色,性价比非常高,值得报考
#头条创作挑战赛# 全国大学校名中有“理工”二字的高校不少,比如北京理工大学、大连理工大学、华南理工大学等等,但这些都是985、211双一流高校,对于大多数孩子来说,可望而不可即,…
-
酒桌上的礼仪和说话技巧
一、敬酒词大全: 1、 床前明月光,疑是地上霜,举杯约对门,喝酒喝个双。 2、 天蓝蓝,海蓝蓝,一杯一杯往下传。 3、 喝完啤酒,喝白酒,黄金白银咱都有。 4、 要让客人喝好,自家…
-
大盘点显手白又高级的秋冬美甲合集?美甲图片大全2022新款式!
#头条创作挑战赛# 新一轮的降温来了,北方的不少地方进入初冬模式~ 在暮秋初冬之际,来一个秋冬美甲大盘点吧!显手白、有秋冬感、有质感要高级,这一期统统满足! 谁能拒绝温柔呢~ 琥珀…
-
提醒中老年人,这4种“洗肠菜”要多吃,润肠又通便,体重蹭蹭降?便秘最怕的9种水果!
大家好,我是琦哥。很多年龄大的朋友,缺少运动,加上天气寒冷,吃的滋补食品太多,造成通便不畅,产生很多有害的毒素,长期以往会导致肥胖、产生口臭和体臭,影响身体健康! 这4种菜是“天然…
-
颈椎病可以治疗好吗?颈椎病的治疗方法。
颈椎病可以治疗好吗?颈椎病的治疗方法。 颈椎病是一种常见的疾病,尤其是在现代社会,由于长时间保持不良姿势、久坐等原因,越来越多的人受到颈椎病的困扰。那么,颈椎病到底可以治疗好吗?本…
