
《科创板日报》4月13日讯(编辑 郑远方)当地时间4月12日,微软宣布开源DeepSpeed-Chat,帮助用户轻松训练类ChatGPT等大语言模型,人人都有望拥有专属ChatGPT。
开源地址:https://github.com/microsoft/DeepSpeed
OpenAI之前明确表示拒绝开源GPT-4,也收获了无数“OpenAI并不open”的吐槽。而AI开源社区已推出LLaMa、Vicuna、Alpaca等多个模型,帮助开发者开发类ChatGPT模型。
即便如此,现有解决方案下训练数千亿参数的最先进类ChatGPT模型依旧困难,主要瓶颈便在于缺乏RLHF训练普及——而微软本次开源的DeepSpeed-Chat,便补齐了最后这一块“短板”,帮助在模型训练中加入完整RLHF流程的系统框架。
仅需一个脚本,便可以完成RLHF训练的全部三个阶段,类ChatGPT大语言模型生成唾手可得,堪称“傻瓜式操作”。
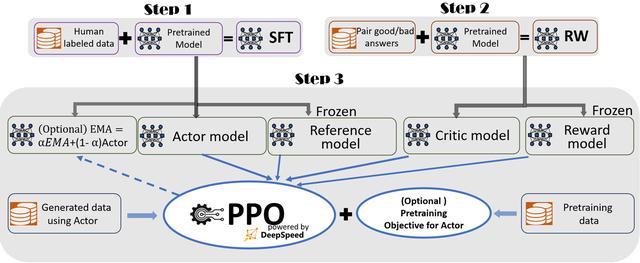
图|DeepSpeed-Chat的RLHF 训练流程图示,包含了一些可选择功能(来源:微软)
这还不是DeepSpeed-Chat唯一的优势,微软提供了中、英、日三语文档,作出了详细介绍。总体来说,其核心功能与性能包括:
1. 简化类ChatGPT模型训练、强化推理体验。
2. DeepSpeed-RLHF模块复刻了InstructGPT论文中的训练模式。同时,DeepSpeed将训练引擎与推理引擎共同整合到了一个统一混合引擎用于RLHF训练。
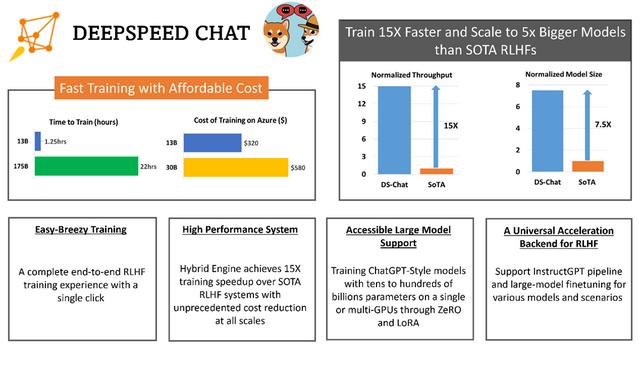
3. 高效性和经济性:可将训练速度提升15倍以上,并大幅度降低成本。例如,DeepSpeed-HE若在Azure云上训练一个OPT-30B模型,仅需18小时、花费不到300美元。
4. 卓越的扩展性:可支持训练数千亿参数模型,并在多节点多GPU系统上扩展性突出,只需1.25小时就可完成训练一个130亿参数模型。
5. 实现RLHF训练普及化:仅凭单个GPU,DeepSpeed-HE就能支持训练超过130亿参数的模型。因此无法使用多GPU系统的数据科学家和研究者,不仅能创建轻量级RLHF模型,还能创建大型且功能强大的模型。
此外,与Colossal-AI、HuggingFace等其他RLHF系统相比,DeepSpeed-RLHF在系统性能和模型可扩展性方面表现出色:
就吞吐量而言,DeepSpeed在单个GPU上的RLHF训练中实现10倍以上改进;多GPU设置中,则比Colossal-AI快6-19倍,比HuggingFace DDP快1.4-10.5倍。
就模型可扩展性而言,Colossal-AI可在单个GPU上运行最大1.3B的模型,在单个A100 40G 节点上运行6.7B的模型,而在相同的硬件上,DeepSpeed-HE可分别运行6.5B和50B模型,实现高达7.5倍提升。
因此,凭借超过一个数量级的更高吞吐量,DeepSpeed-RLHF比Colossal-AI、HuggingFace,可在相同时间预算下训练更大的actor模型,或以1/10的成本训练类似大小的模型
生意营销3大宝:彩铃、定位、认证,一个也不能少,如有需要,添加 微信:xnc528 备注:3
如若转载,请注明出处:https://www.clzz8.com/45421.html
相关推荐
-
5大品牌12个维度筋膜枪横评,实际感受测试?筋膜枪是震动的吗!
本内容来源于@什么值得买APP,观点仅代表作者本人 |作者:Lucy轻一度 一、导语 包括使用筋膜枪在内的现代养生行为,是打工人给“身体内耗”的反击 每个都市人都需要筋膜枪,并非夸…
-
还记得“欧阳夏丹”吗?离开央视后久违露面,网友爆料她已离婚,欧阳夏丹孙正军
近日,许久未露面的前央视主持人欧阳夏丹通过自己的社交媒体露面,并教给大家如何保护嗓子。 在视频中,欧阳夏丹一上来就告知大众一定要保护嗓子这件事,如果在工作生活中必须使用嗓子,那么最…
-
三种人不宜拜如来佛祖图片,为什么不拜如来佛祖?
清华大学人文学院教授 沈卫荣 本文系作者2022年7月14日在四川大学铸牢中华民族共同体意识研究基地的线上讲座,由清华大学中文系“水木学者”博士后侯浩然整理。全文分两部分刊出,这是…
-
华为手机全部价格表及图片华为手机全部价格表及图片下载!
9月6日下午,华为举办Mate 50系列及全场景新品发布会,一口气推出了多达18款产品,涵盖智能手机、手机壳、电动汽车、笔记本、平板机、墨水平板、台式机、智能手表、无线耳机、智能眼…
-
阿里推出GPT全家桶,一把手亲自抓的“神仙打架”,能超越OpenAI吗?
“终于有了一个AI‘嘴替’,它叫‘鸟鸟分鸟’。” 4月4日,知名脱口秀演员鸟鸟展示了她的语音助手——搭载在天猫精灵上的类GPT模型,不仅能对答如流,还能模仿她的音色、语气与文本风格…
-
穿牛仔裤时,搭什么鞋子才够好看?推荐这4双,气质、显贵、优雅
牛仔裤作为日常穿搭必不可少的经典单品,几乎成为了每个人衣橱里的标配。它时尚百搭,适合各种场合,不仅能展现出个人的气质和品味,还能给人一种自在随意的感觉。 然而,穿好牛仔裤并不容易,…
-
2023紫微星降世知乎,2023紫微星降世原帖?
1、八五花咖位掉了吗? 八五花的咖位是在那里摆着的,在电视剧圈,尤其是古装剧圈子里,八五花绝对是第一梯队top级别的。昨天“八五花齐聚横店搞事业”这个词条突然上热搜,就有小婊贝问她…
-
制作微信彩铃怎么弄,怎么制作微信彩铃?
制作微信彩铃怎么弄,怎么制作微信彩铃? 微信彩铃是一种可以在微信聊天界面中播放的音频文件,可以让你的聊天更加有趣和个性化。下面是制作微信彩铃的方法: 1. 找到一首你喜欢的歌曲或音…
-
年轻妈妈衣着暴露在儿子面前大秀伦巴,引发网友激烈讨论
年轻妈妈衣着暴露在儿子面前大秀伦巴,引发网友激烈讨论 网上一段年轻母亲在儿子面前大秀舞姿的视频引发了网友的激烈讨论。如果仅仅是一段表现家庭和谐的互动视频并不会招致非议,而视频中的母…
-
藤间斋爸爸出轨辟谣,藤间斋爸爸出轨了吗?
5月24日,周刊《女性自身》报道了歌舞伎演员市川染五郎(藤间斋)高中退学的消息。啊…?! 电视剧、杂志、歌舞伎…正努力地发展事业的染五郎私下里却做了一个“悲壮的决定”。 虽然从幼儿…
